The process of transforming my research question to suit the concerns of network analysis taught me a great deal about Gephi. I quickly learned that the approach I took to my general research interest in mapping the relationship between the cartographer and the rastaman through place in Kei Miller’s The Cartographer Tries to Map a Way to Zion was not so much concerned with relations within the text as simply visualizing geography. Instead of attempting “to portray a new unfamiliar territory” I only considered portraying a familiar one (Lima 80). With some more thought about relationships between words that may be fruitful to my research I came to was: How are words that signify systems of measure used beyond “Quashie’s Verse” — the poem in the collection I am most familiar with. This included rereading the collection and looking out for words that are related to measurement of some kind. For additional efficiency I searched for keywords in an electronic copy when I identified them in order to see if the word was repeated elsewhere in the poetry collection. Though I considered using Voyant to do a differential reading I decided against it because I was focused more on specific word choice than on word frequency for example, so it was necessary to do a close reading. Examples of the words I found are “measure”, “arc”, “distance”, “miles” and “length” — each appearing at different frequencies. The process of creating the nodes and edges table prompted me to read around the words I found, for some words surprised me, and I discovered language of measurement is almost only used by the rastaman and not the cartographer. What was not so surprising was that he uses these words to demonstrate the indeterminacy of European systems of measure, or the “immappancy of dis world” (Miller 21). With this in mind I was more prepared to delve into the cartography of networks.
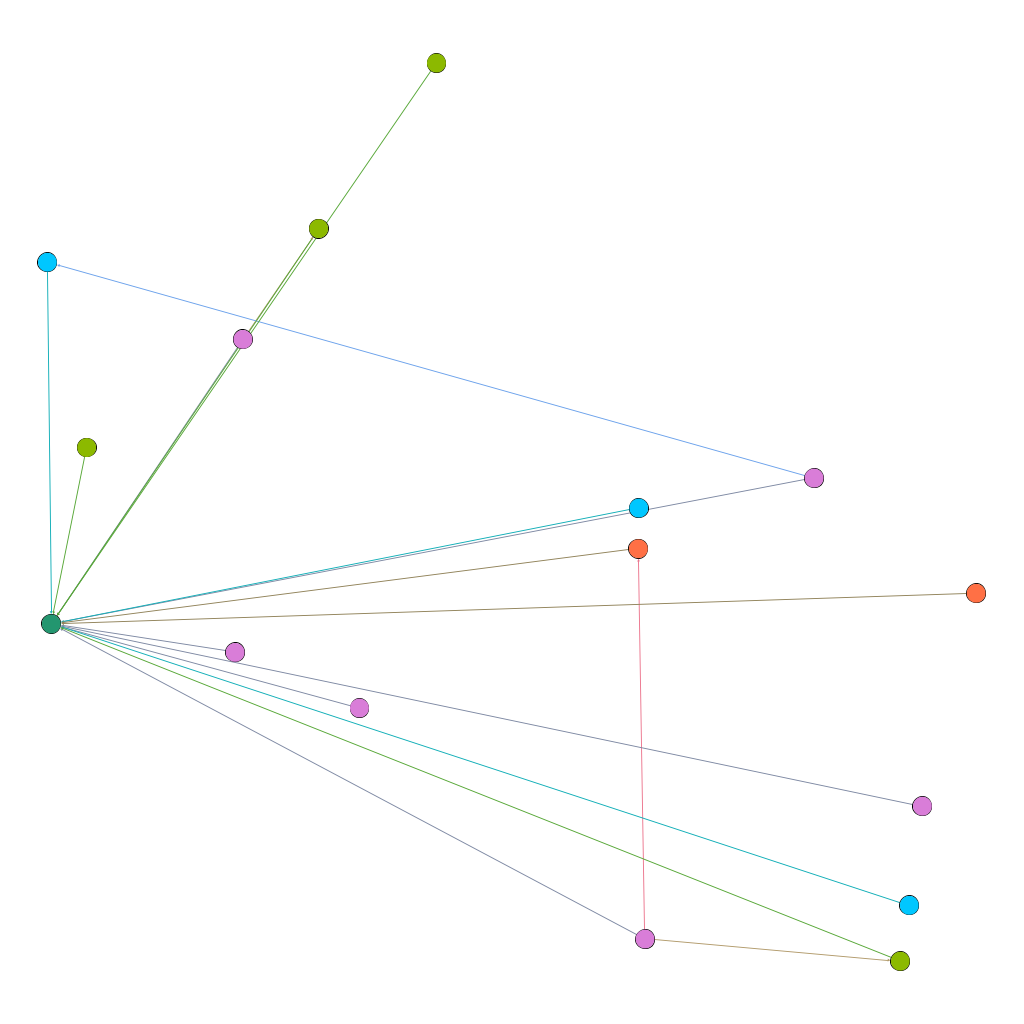
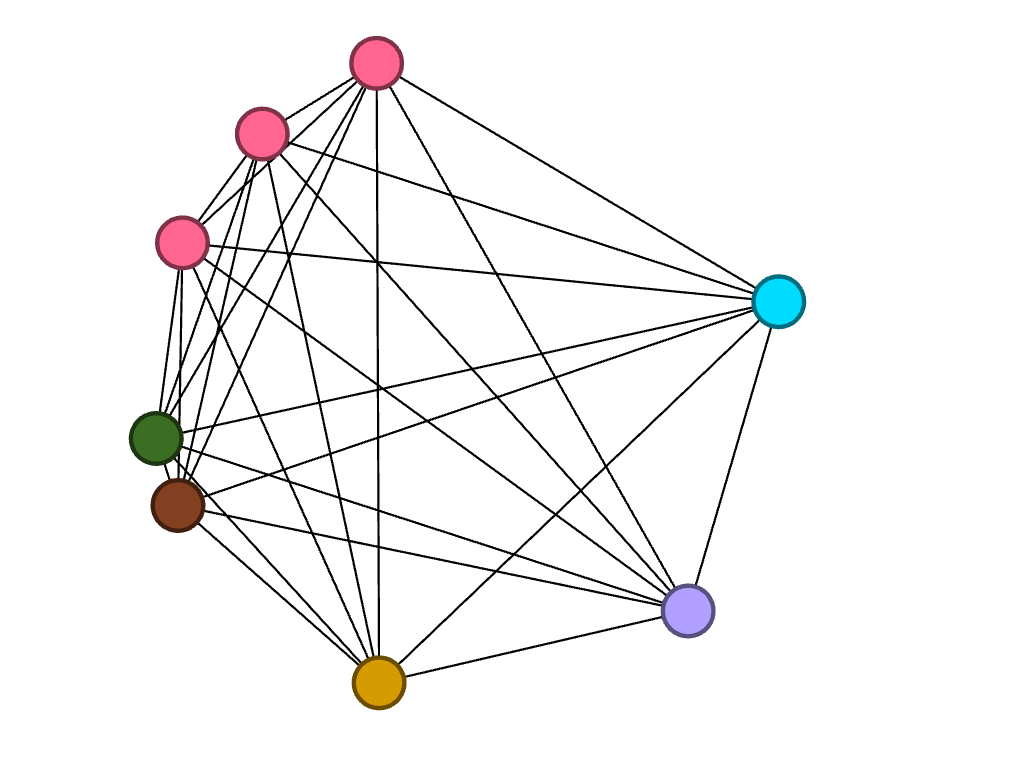
Creating the visualization allowed me to map the relationships between words related to metric in Kei Miller’s The Cartographer Tries to Map a Way to Zion. This was particularly fruitful considering the cartographic concerns of the text. The nodes are words signifying systems of measure, and the edges represent occurrence in the collection, which each word is attributed to a particular poem in the collection.
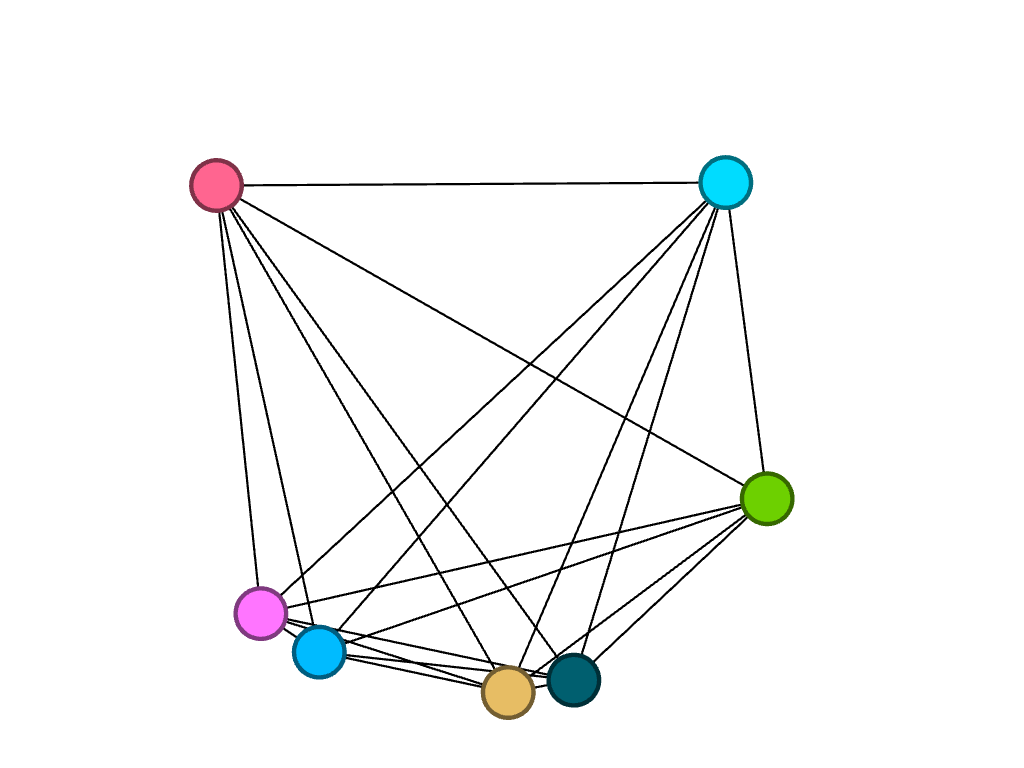
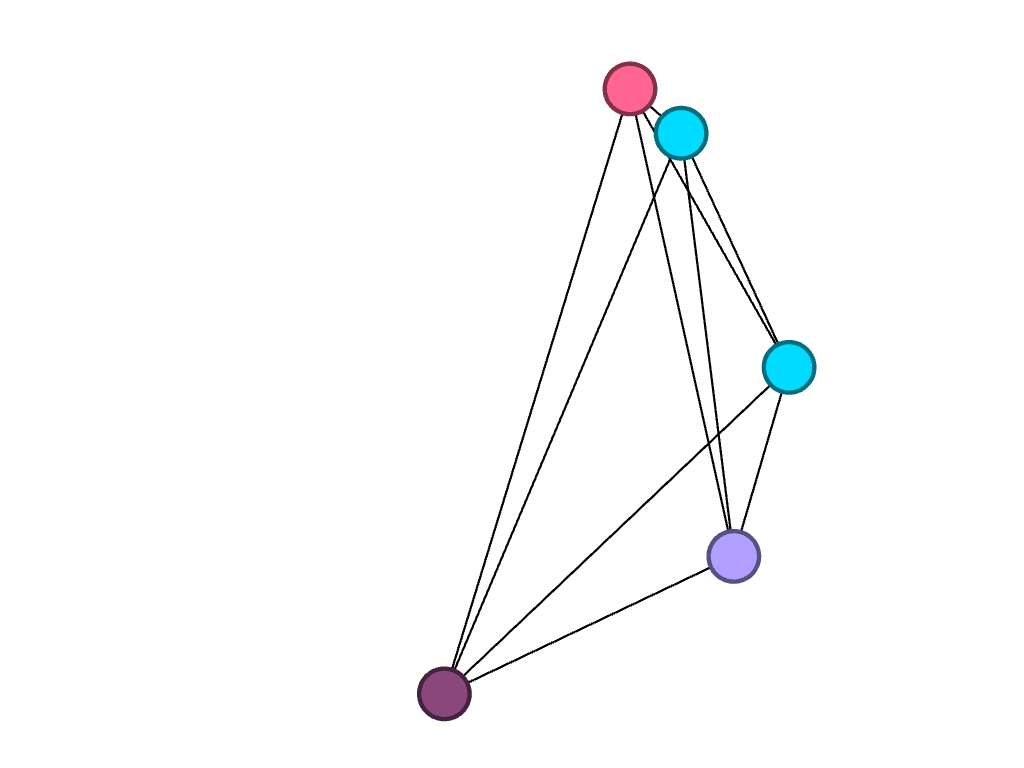
This is an ego network, where the words the rastaman uses concerning measurement are linked to him, and each node is partitioned according to degree, the colors of the nodes and edges representing the poems that have the most connections in the network. However, I did not find this method of visualization particularly illuminating.
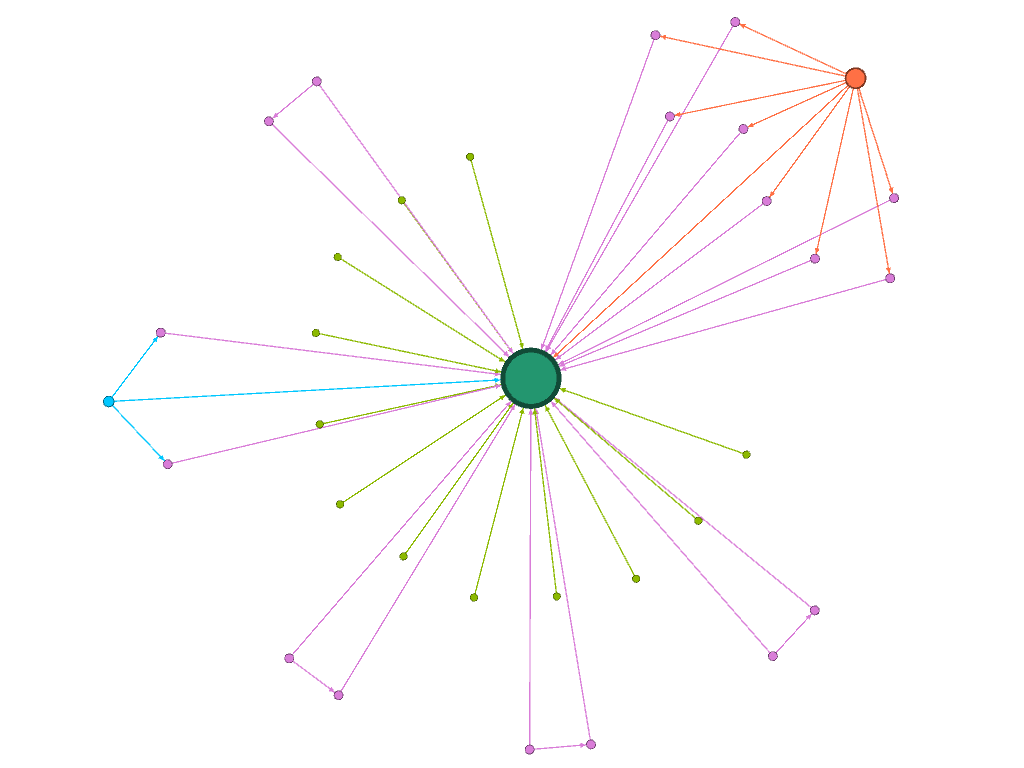
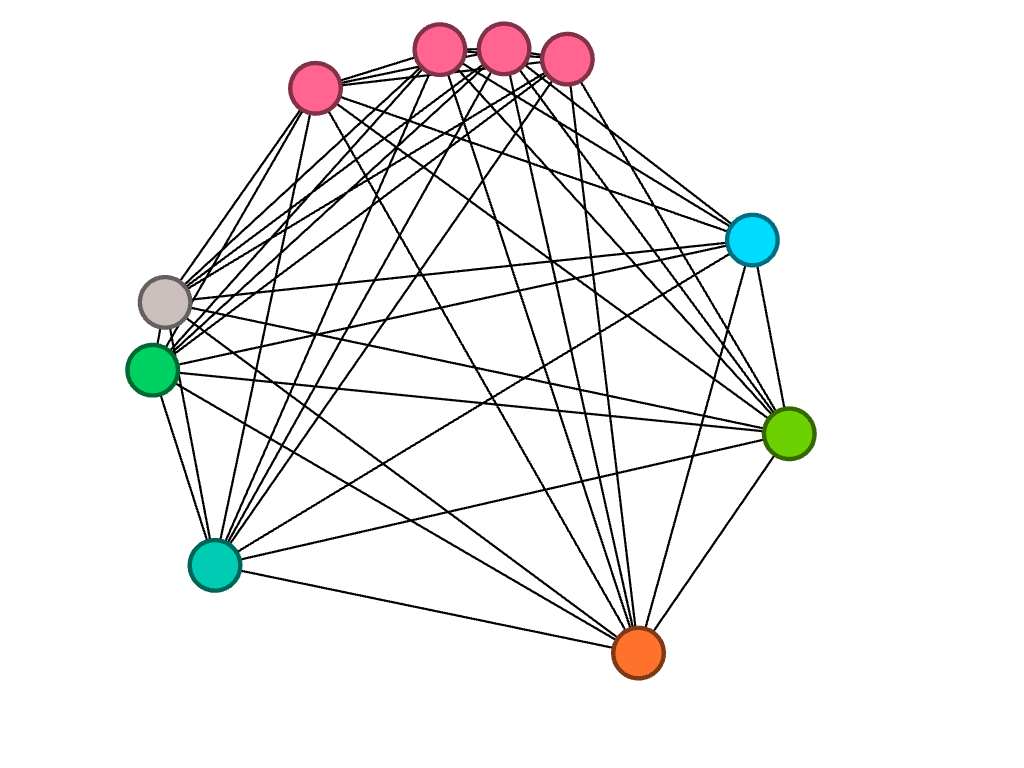
I was fascinated by the shape proceeded so I did not change the layout. Instead I partitioned by modularity class and found the results eyeopening. Seeing the communities of poems grouped according to the linguistic connections between them gave me more insight on Miller’s project with his collection. It reaffirmed Lima’s statement that “network visualization is also the cartography of the indiscernible, depicting intangible structures that are invisible and undetected by the human eye” (Lima 80).
I felt more confident about my choices knowing that “The best community detection approach is the one that works best for your network and your question; there is no right or wrong, only more or less relevant” especially since I am not mapping a community of people, but rather a community of words (Graham 229). Reading Graham’s work was particularly helpful to understand the elements of networks in general and each of the functions on Gephi in particular. Moreover, the approaches to creating a network in practice were useful. Instead of sticking to what I thought was the only “correct” way to proceed – a Hypothesis-driven network analysis – I felt free to be more exploratory, knowing “that the network is important, but in as-yet unknown ways” (Graham 236).

For my final visualization I chose to use a black background to highlight not only the color but also the unique shapes produced by the network. The shape at the top right corner was of particular interest because it resembles a spider. The spider, specifically Anancy, is a figure mentioned in the collection who plays with and plays on language, governing the process of interpretation. Seeing a version of Anancy appear in this new map prompts me to think more about how maps can be visible or invisible, and ways that lines, measurements and algorithms may be humanistic. “You cyaa climb / into Zion on Anancy’s web – or get there by boat or plane or car” (Miller 62). This web invoked by the visualization does not arrive at Zion, in the same way the cartographer discovers there is no one way to map a place that is not quite a place.