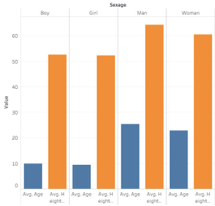
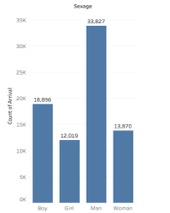
When we break down our day to day life, we are constantly networking. Whether it be adding someone on LinkedIn, friending someone on Facebook, following someone on Instagram, or even texting a friend of a friend who had your professor in the past. Who ever it may be, it is hard for us to go an hour without networking. Over the summer, the most frequent piece of advice I was given was to network. Whether I was introducing myself to a Bucknell alumni, an employee from Darien, or my older sister’s best friend’s ex boyfriend, I was constantly establishing connections with people. Some relationships I was more invested in than others. For example, I placed more weight on my relationship with my boss than I did with a Bucknell graduate working in a different department. However, if you were to look at my boss’s network, I am sure the weight placed on the connection that bounds us together is a lot less for him. Recognizing this, we understand that a network “we need to be extremely careful when analyzing networks not to read power relationships into data that may simply be imbalanced” (Graham, 197). Further, it is important to understand that when we consider a network, “it is easy to become hypnotized by the complexity of a network, to succumb to the desire of connecting everything and, in so doing, learning nothing” (Graham, 201).
Due to our tendency to hyper-analyze networks, it is important to build one with with a research question in mind. Essentially, this question will “act as your yardstick to measure effective outcomes” (PPT). With this in mind, I dove into the dataset of Diseasomes, which is a complied spreadsheet of diseases and genes, with an exploration question that resognated with me personally.
I first noticed the signs in 2014. It was that summer that Alzheimer’s entered my life and infected my grandmother. Alzheimer’s is a progressive disorder that causes brain cells to waste away degenerate and die. As of now, there is no cure. Since 2014, my mother has exposed us to a new lifestyle in which we have become a lot more conscious about the way we treat our bodies. I am conscious about what I eat, what I drink, how much I work out, how much I sleep, and what I put in my body in general in regards to vitamins, medicines, pain killers (Advil), etc. Although known as a neurological disease, I’ve seen my grandma lose a significant amount of mobility in her legs, hands and mouth. These symptoms are not notorious ones within Alzheimers patients. Using the Diseasome dataset and Gephi’s platform, I want to interpret genes, diseases, and specifically, Alzehimer’s, further.
The purpose of my analysis is to uncover whether neurological diseases are intertwined with a specific gene that might trigger loss of mobility. This might explain why my grandmother, and possibly other patients, are experiencing symptoms that do not align to Alzheimer’s. I am looking for a “general trend” within the network of neurological diseases and specific genes (Graham, 198).
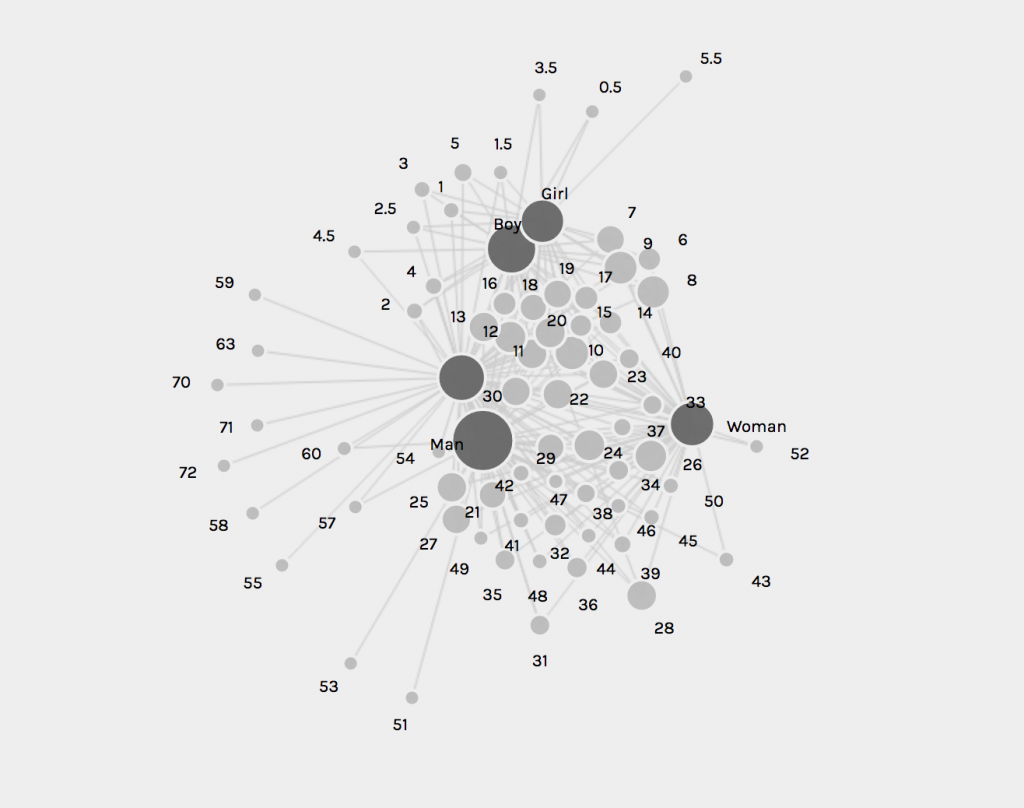
I originally looked at the data unfiltered and without edges. I looked only at the nodes of all diseases and genes included in the study. It is important to note that a node is simply an entity and edges refer to the relationships between edges and nodes. Essentially “everything about a network pivots on these two building blocks” (Graham, 202). I wanted to get the big picture and be able to visualize both classes of disease and gene at the same time knowing that mutations in genes influence the oncoming of diseases.
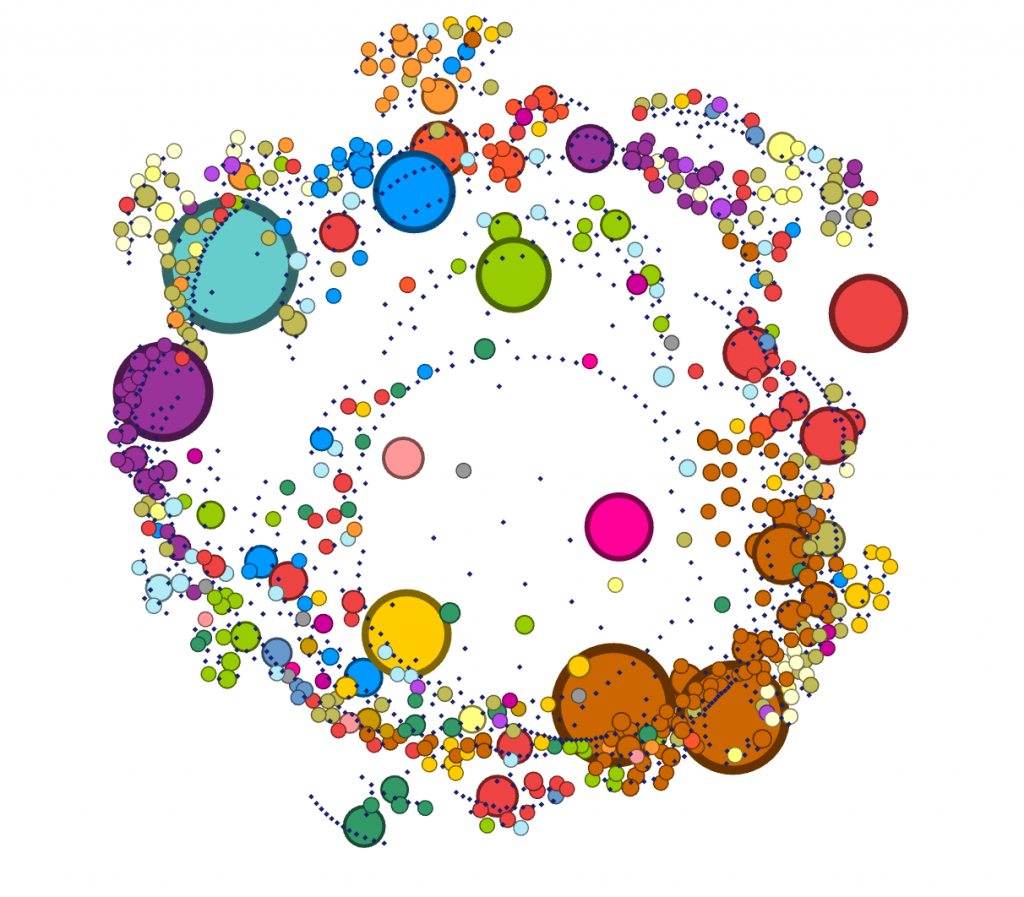
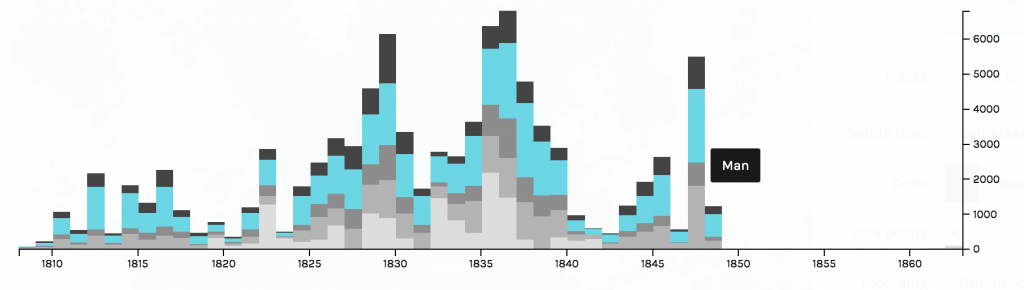
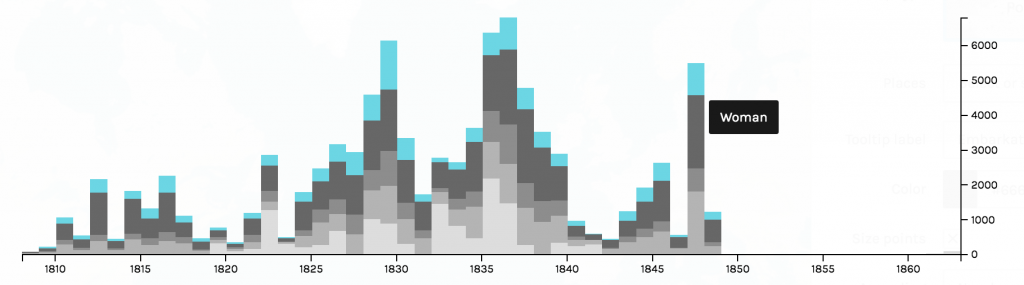
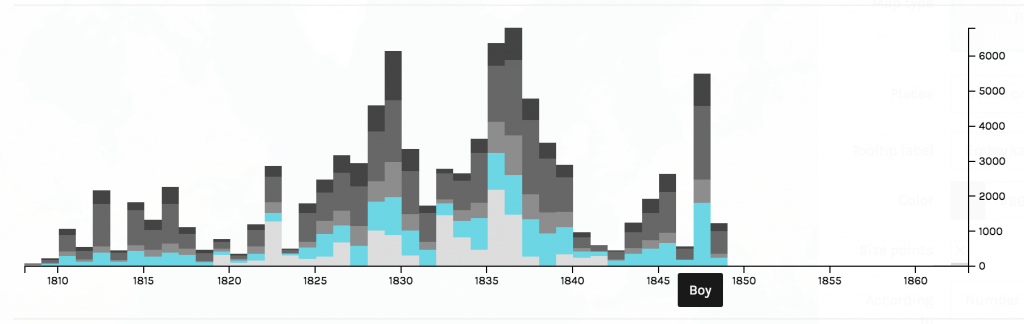
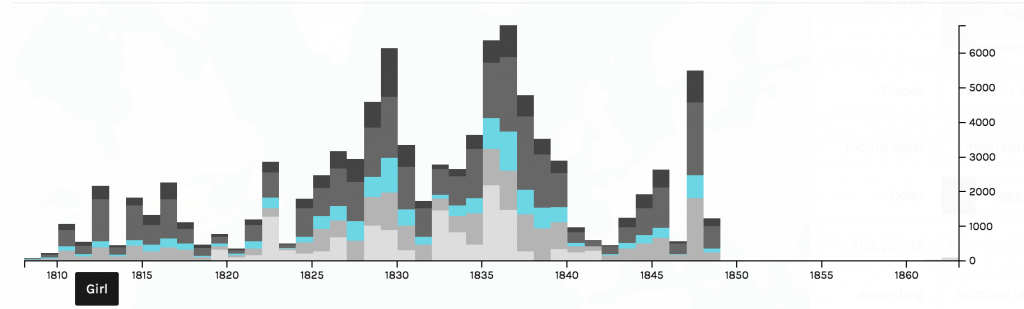
I, then, filtered the nodes to only show neurological diseases. Using this filter process, I am able to see how much of the data is a neurological disease. Approximately 3.88% of the data collected was on neurological diseases, some of that data being Alzheimer’s.
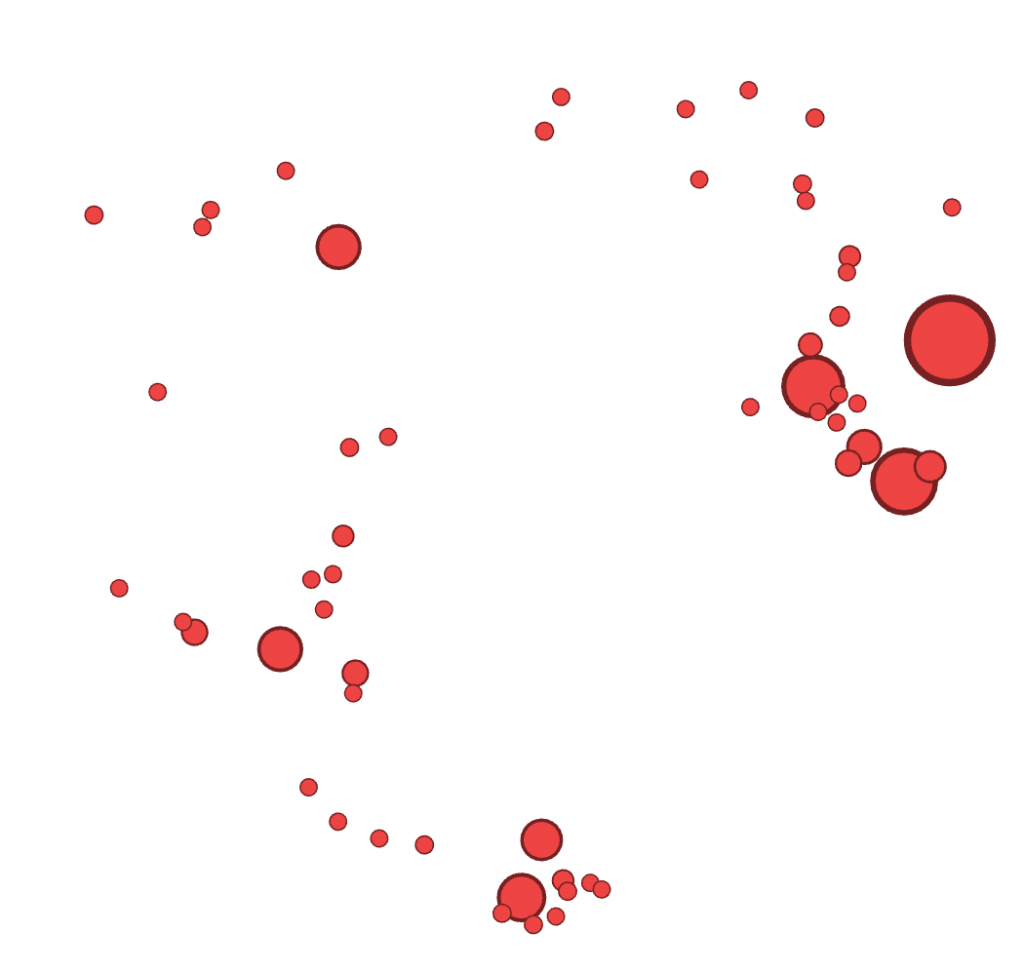
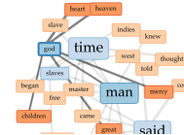
For such a large dataset, such a small amount of the data is focused on neurological diseases. I continued filtered the data to show inter edges within the neurological diseases world. Inter- means between or among groups, therefore connections will be shown between diseases and genes. My decision to filter the data by inter edge using neurological disease as the parameter was because I wanted to be able to visualize the relationships between neurological diseases and genes included in the study. This tool is an exceptional one because I was able to visualize “intangible structures that are invisible and undetectable to the human eye”, for example, all the many genes that a mere imbalance of can result in a neurological disease (Lima, 80).
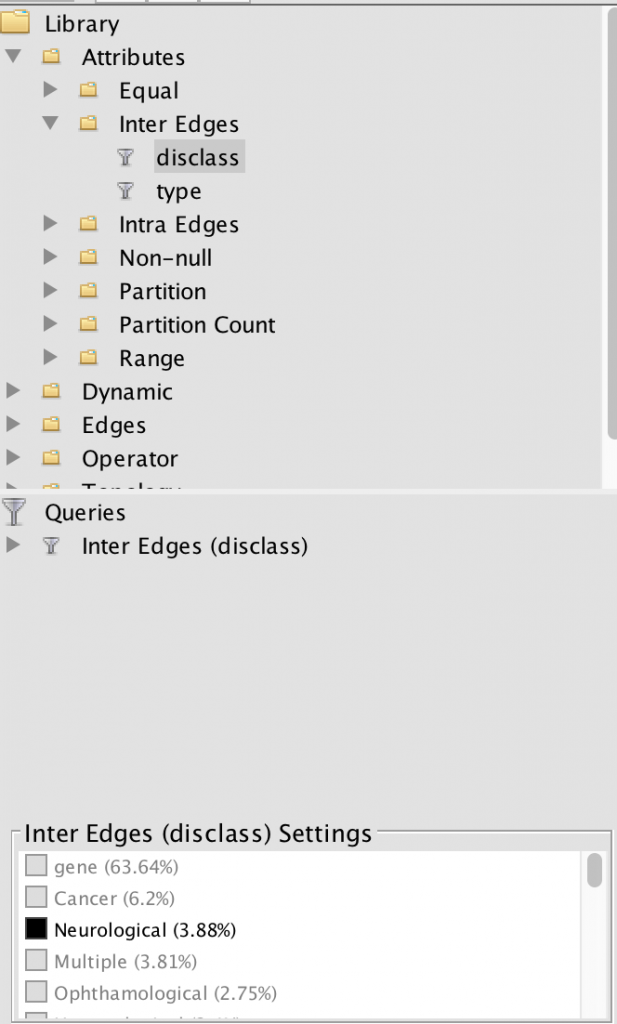
I then proceeded to analyze the dataset further in the Data Library. I saw that not all the connections that appeared within the inter-edge visualization were not red, meaning some of the diseases had ties to other genes – possibly one related to motorized skills one that would explain the situation going on with my grandma. In the Data Library, I again filtered the data to show inter edges. I knew that the ID number of Alzheimers in this dataset was 30. I filtered the Source to be ID: 30, and waited for the Target numbers to appear. I ended up with this list of genes that shared a relationship with Alzheimers. One set back I faced was I then had to take the ID numbers of the targets and look up their gene name on the master dataset. However, once I did this, I looked each of them up to see if any had a relationship to Alzheimers or other diseases that experience these symptoms.
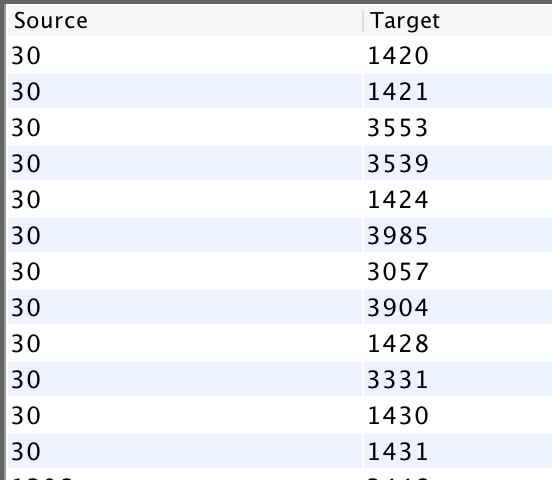

In the end, I found that the gene MPO is a key enzyme in inflammatory and degenerative processes. Many Alzheimer’s and Parkinson’s disease patients have increased levels of MPO protein. MPO causes motor cortex disabilities, meaning the part of the brain that initiates voluntary muscular activity is affected.
There is no scientific backing to the conclusion I came to, however, it does provide some reassurance to me that what my grandma is experiencing is in fact a part of her disease. The network I built on Gephi led me to uncover and then research a total of 12 genes and their relationship to Alzheimers that I wouldn’t have otherwise.