I initially became intrigued with the ship, the Mary, after being introduced to the Trans-Atlantic Slave Trade Database in the beginning of the semester. I wanted to know more about the specific ship and what it could tell me when it was separated from the records in the database. This concept was inspired by the argument made by Segel and Heer: “while stories often concern interacting characters, they may also present a sequence of facts and observations linked together by a unifying theme or argument” (Segel & Heer), and ultimately led me to my research question: what happens to the hairball of Trans-Atlantic Slave Data when I drill down and look at a particular ship? In order to answer my question, I had to rely on several digital visualization methodologies that I learned in class this semester because each helped me approach the question from a different angle.
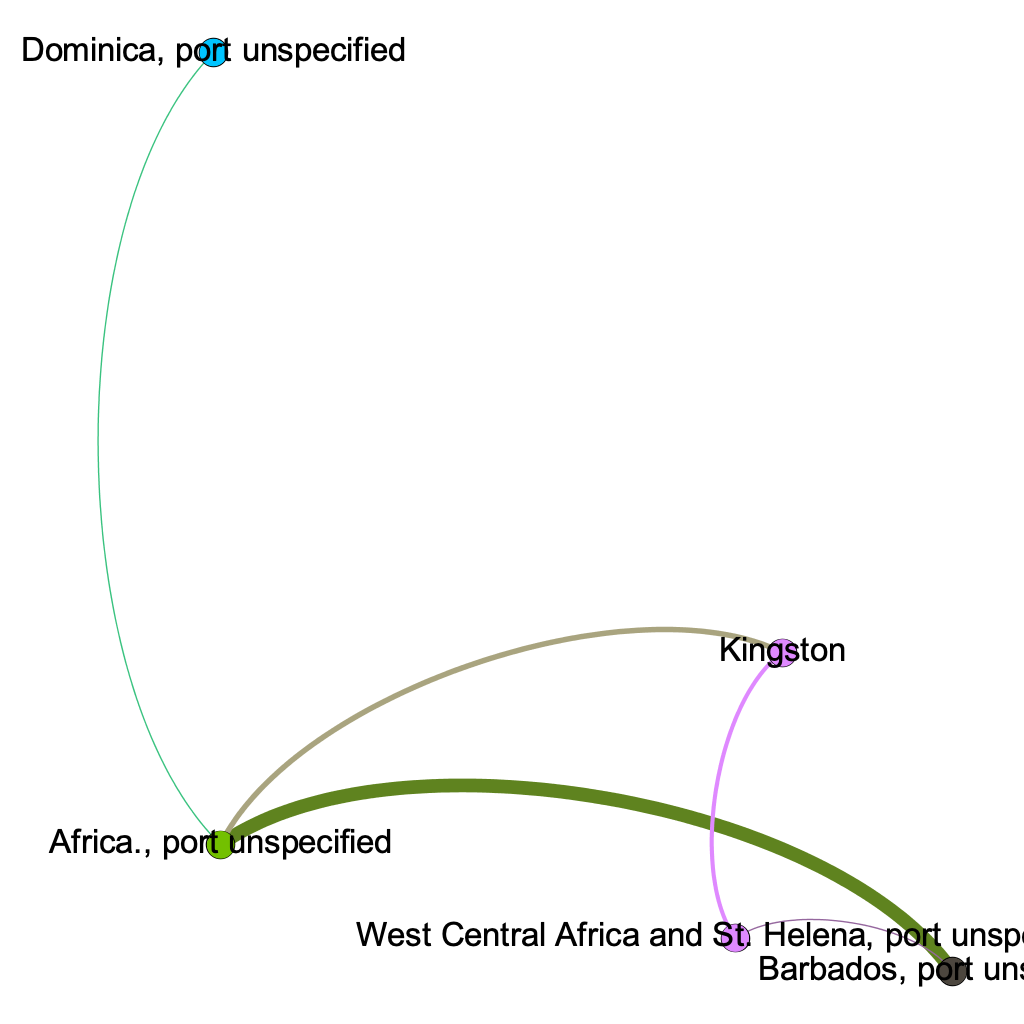
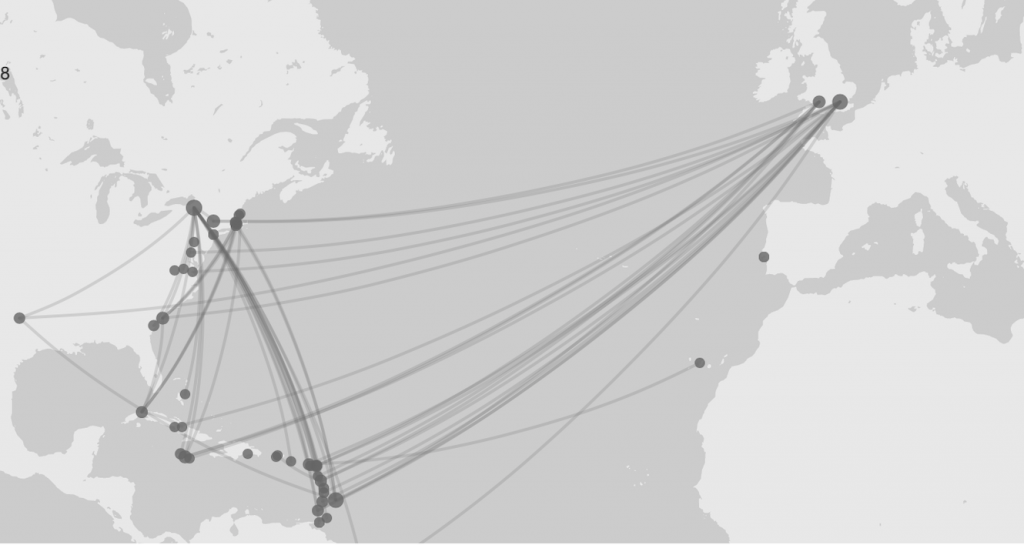
First, I used ArcGIS Online to map the voyages that the Mary took. I created a dataset that consisted of the place of origin for each voyage, the place where the slaves were purchased, and the place the slaves landed. I then had to create a map layer for each set of locations before merging them all together, so that the path taken would show up all on one layer. ArcGIS allowed me to visually illustrate the slave trade and the route that the Mary took. Using the heat map feature, I was able to see that Liverpool, Bonny, and New York were some of the most common places that the Mary visited.
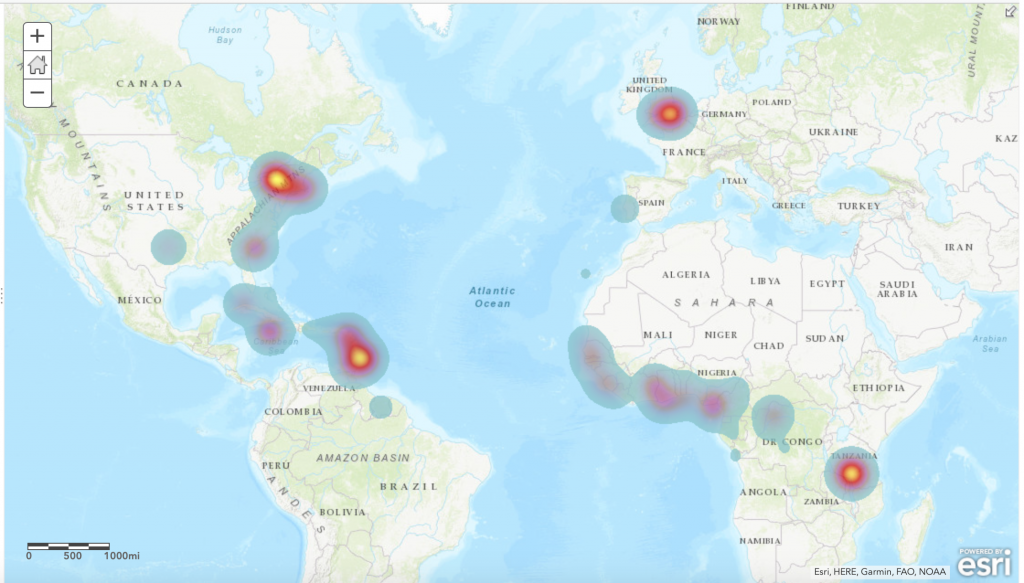
I was then able to drop down pins in those locations and draw lines connecting them to really demonstrate the path the Mary often took. I ran into some difficulty when trying to map the ports on the basemap because the geographical category varied for each location in the Trans-Atlantic Slave Database. Some records used states to share where the Mary went, while others used countries or cities. However, I was able to overcome this by putting a pin on the locations of the ports in the present day, which is pretty accurate.
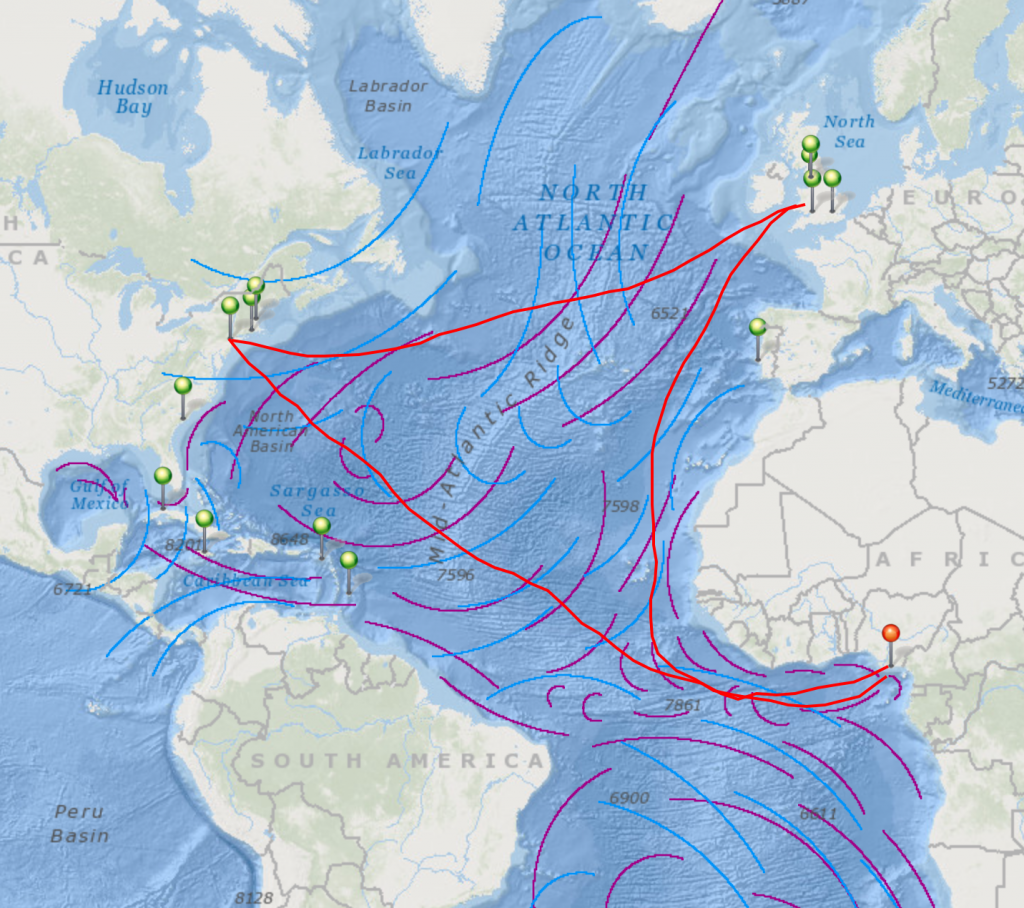
After learning what ports the Mary often went to, I wanted to know more about each location and their significance in the greater Trans-Atlantic Slave Trade. I felt that storymap platform in ArcGIS would best help me convey the story of the Mary because it allowed me to tell the story around each of the locations on the map. I had key locations (Liverpool, Bonny, and New York) on the Trans-Atlantic Slave trade and needed to be able to tell the story of them. Through this process, I learned that not only was Liverpool a common port of origin for the Mary, but it also had a significant role in the Trans-Atlantic Slave Trade. I felt that using ArcGIS was an effective way of addressing my research question, especially because I was working with many locations so the map visual was very beneficial. I found this correlation extremely intriguing and decided to do some more research into the relationship. I learned that the Mary was built in Liverpool too! This finding led me to start researching into the owners of the Mary and the various captains of each of the Mary’s journeys. I thought it would be really interesting to learn about each of these individuals and what their role was in the greater Trans-Atlantic Slave trade. I also wanted to see what their relationships were to each other and how those connections could have impacted events that occurred during that time period.
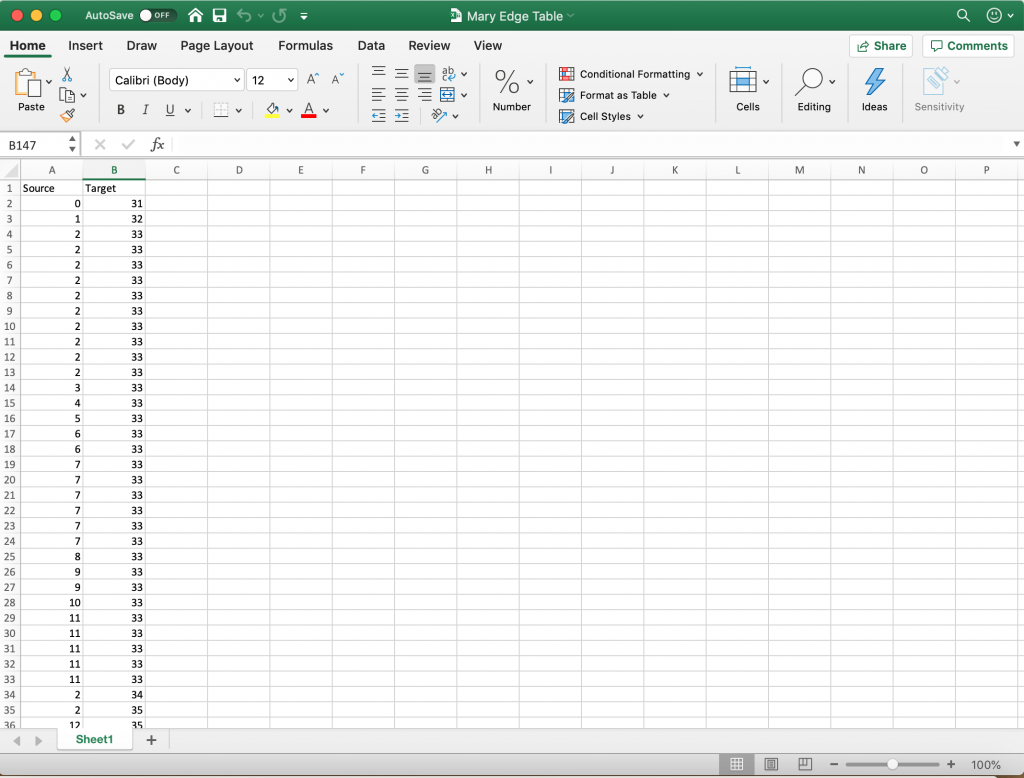
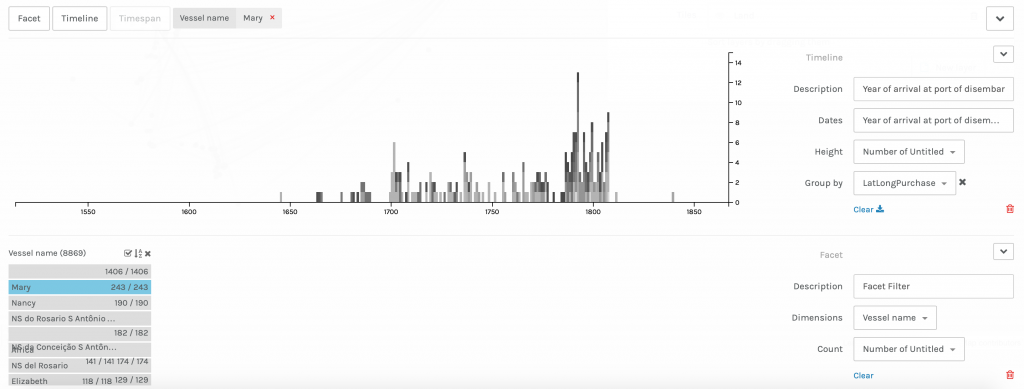
However, I immediately ran into problems when I went back to the database on a quest for more information. I found that because ‘Mary’ is a very common name, there could have been numerous ships with the same name and there was no reliable way of differentiating the ships. There were 243 recorded voyages under the vessel name ‘Mary.’ between the years of 1649 and 1816. However, since my focus was on Liverpool, I filtered the data to only show voyages that began out of Liverpool, which totaled 186. In order to discover the relationships between the different individuals, I had to create a new dataset that included the owner(s) name(s) and the captain(s) name(s).
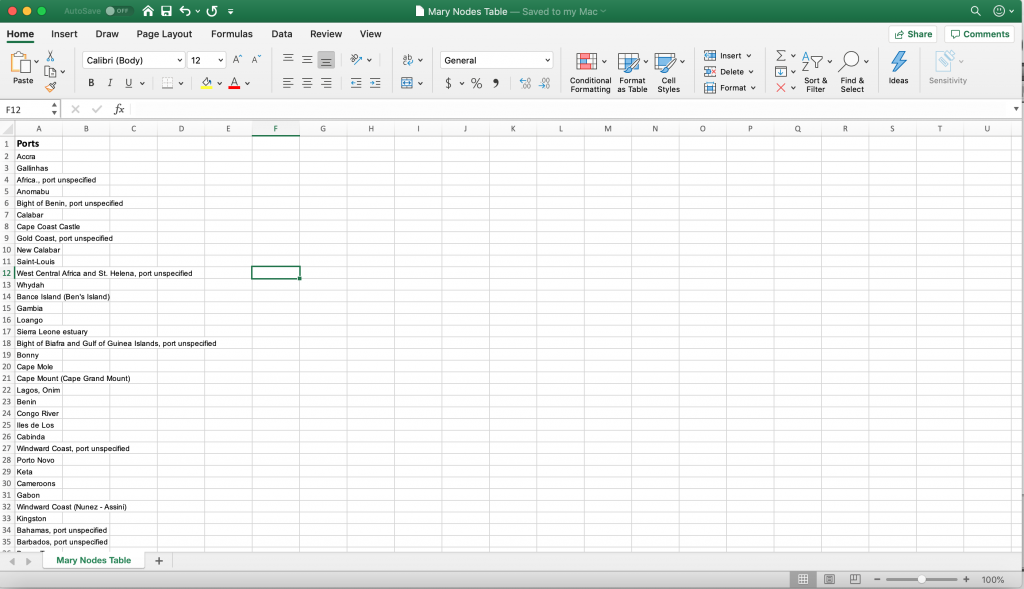
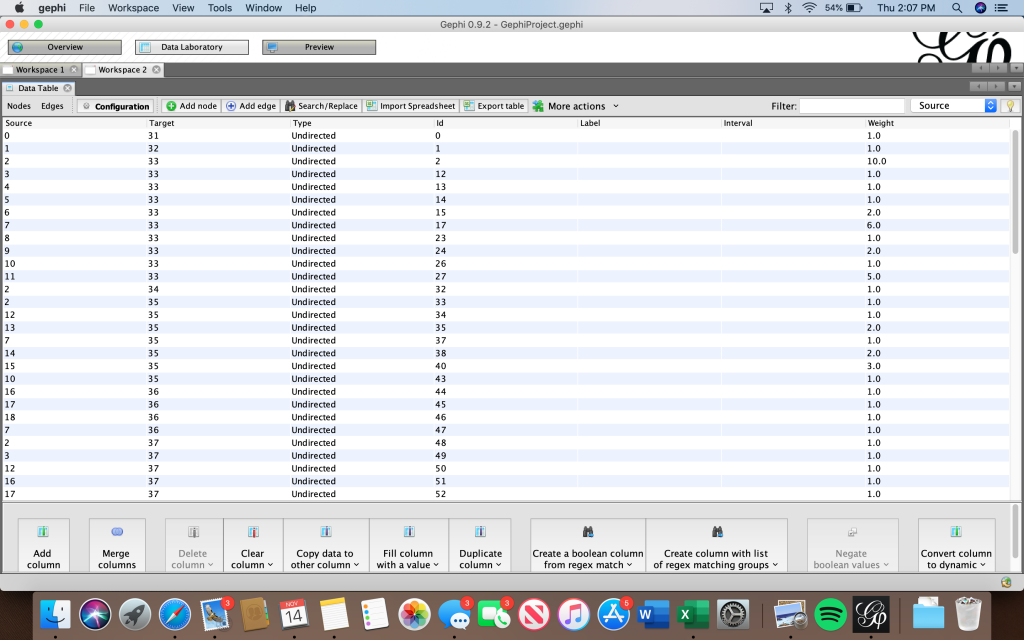
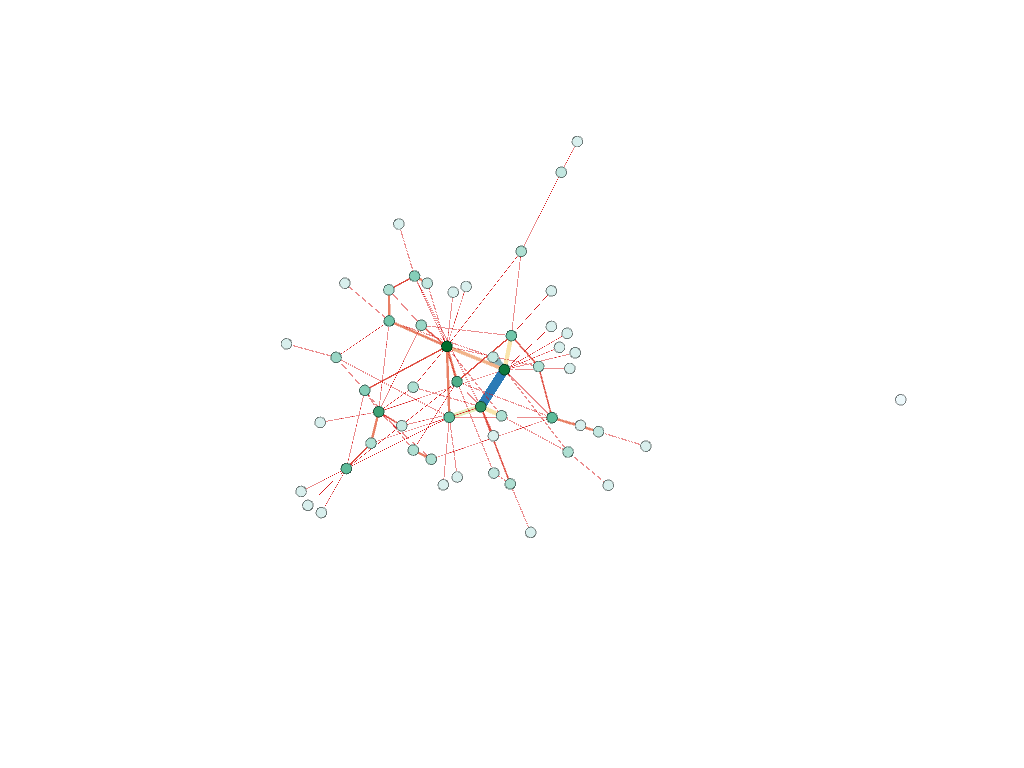
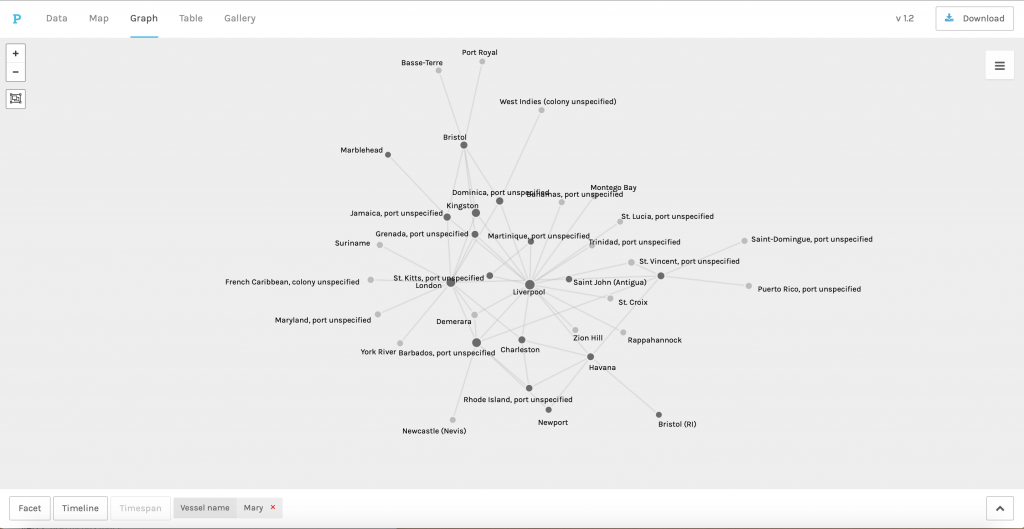
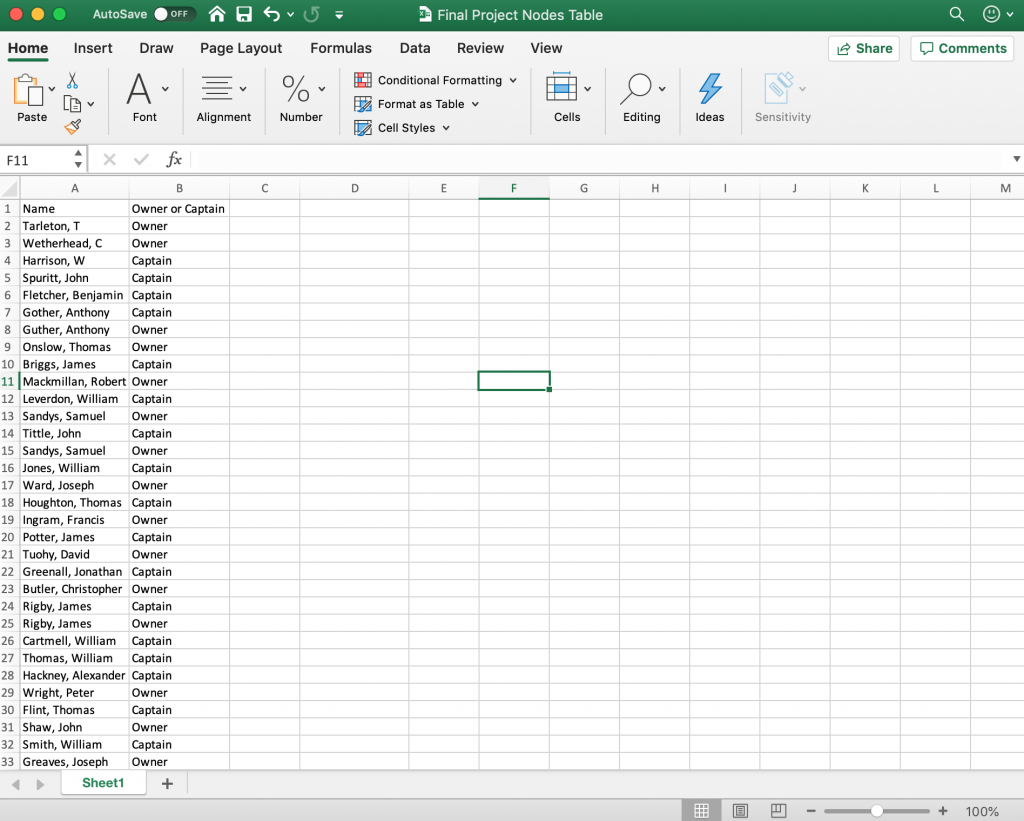
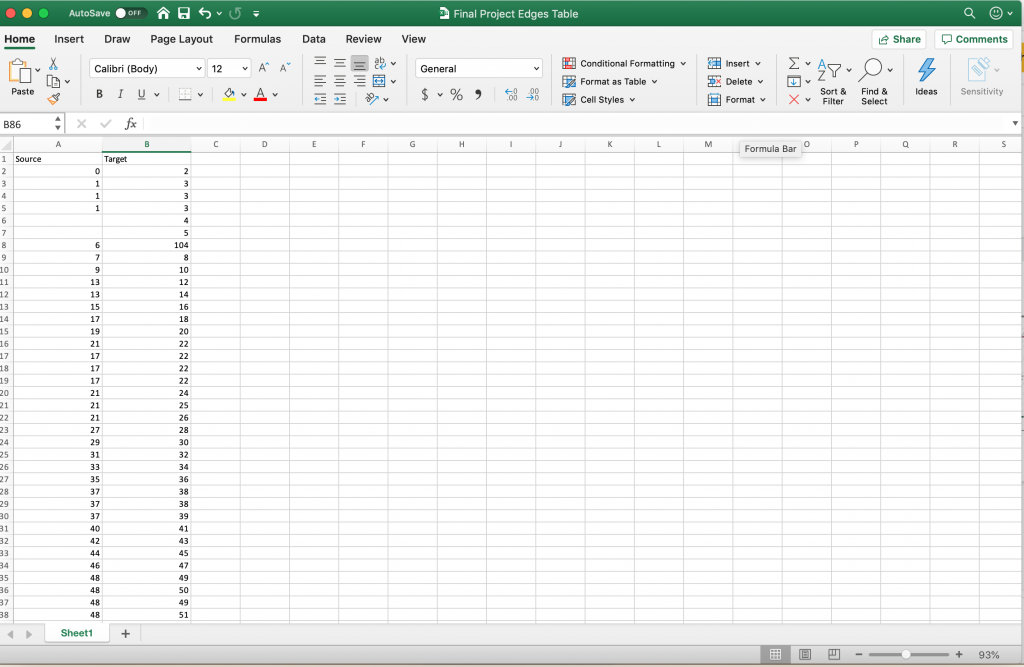
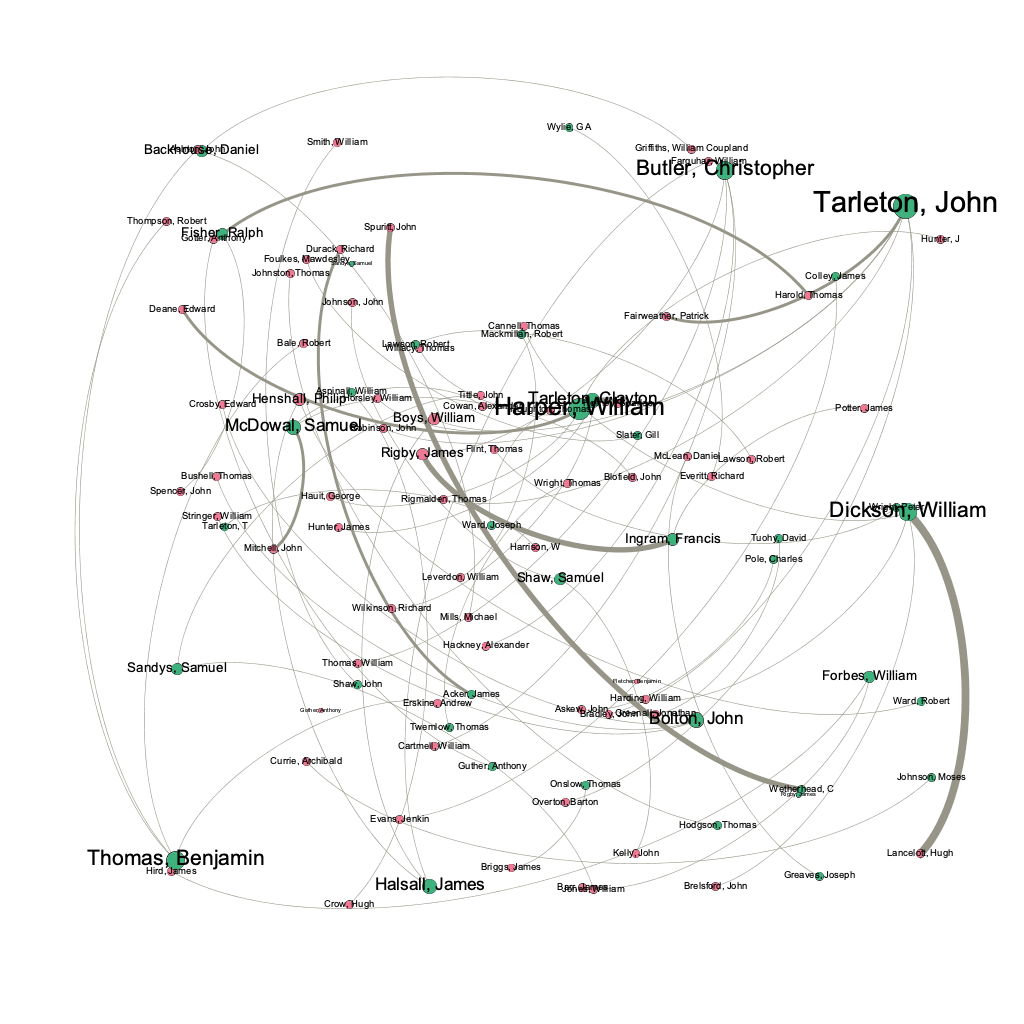
I felt that Gephi would be the best digital visualization methodology to show the relationships among captains and owners of the Mary because the visualizations I can create in Gephi are “the cartography of the indiscernible, depicting intangible structures that are invisible and undetectable to the human eye” (Lima 80). In order to use the platform, I had to again manipulate my data. However, this is where I ran into another problem. For some of the Mary’s voyages, there were multiple owners and multiple captains listed, but Gephi limited me to only using one owner and one captain. To keep things consistent, I used the owner whose name was listed first and the captain whose name was listed first for every voyage. I created a node table, where I listed all of the Mary’s captains and owners. I then inserted the spreadsheet into Gephi and each individual received their own id number. Next, I manually connected the owner of the ship listed for each individual voyage (source) to the captain of the same voyage (target) using each individual’s unique Id number, creating an edge table. Once I uploaded the edge table, I was able to work with the data.
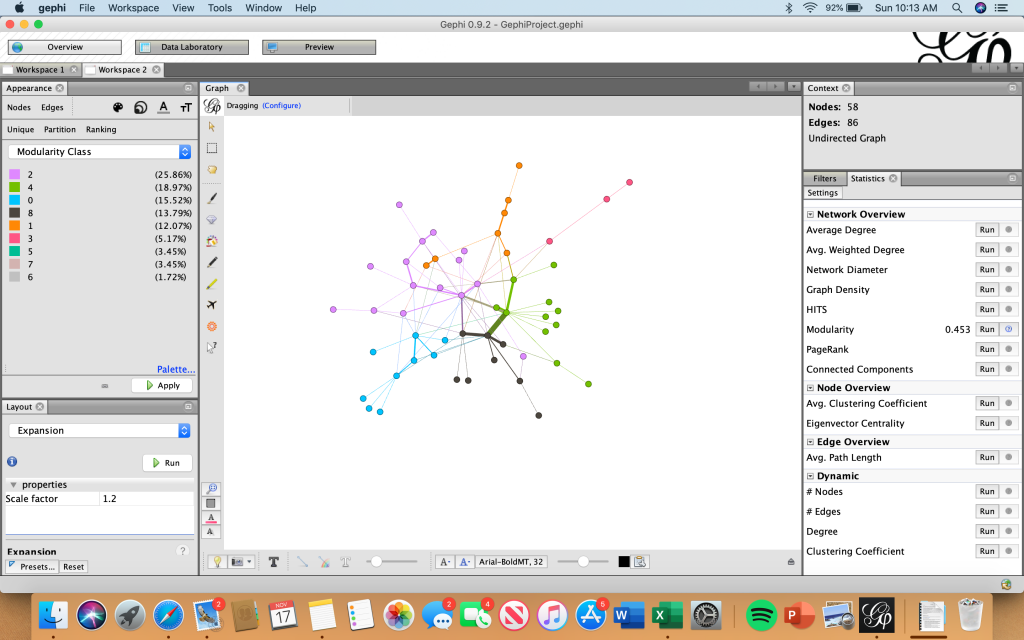
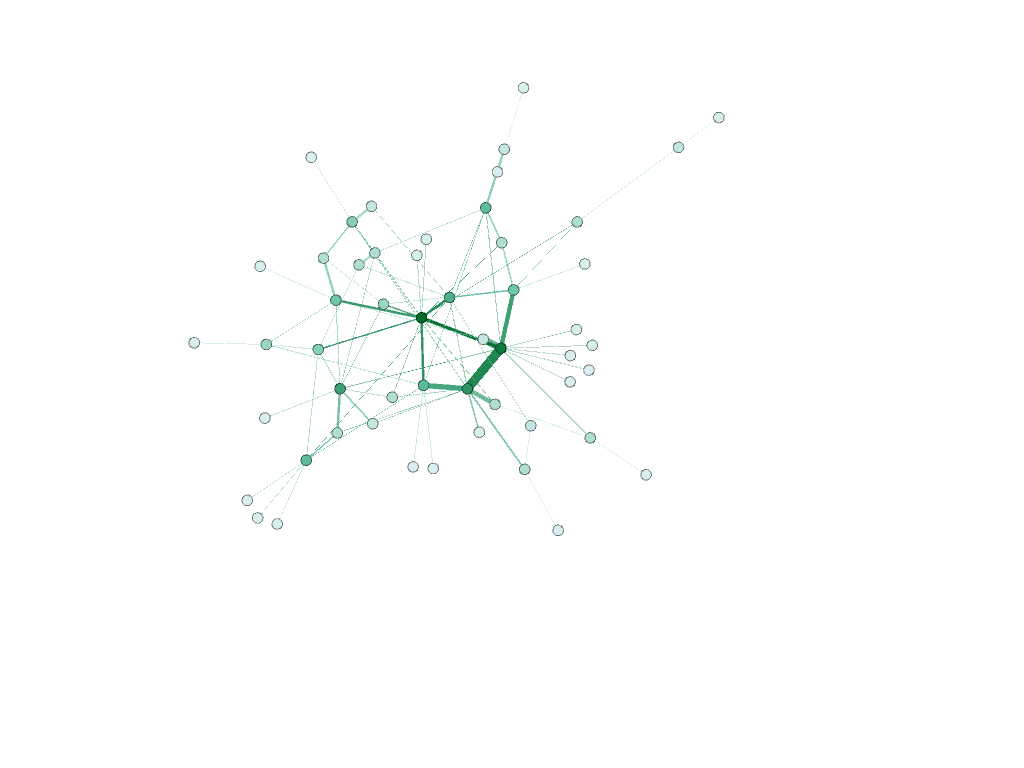
I created a network of people and differentiated the captains from the owners of the ship by making the nodes representing captains pink and owners green. I used the modularity calculation to see if there was a nexus of names that were closely related and then I used the average degree calculation to see how many relationships each individual had. In the visualization I created I made the size of each node represent the degree, so the larger the node, the more relationships a person had. Also, I weighed the edges to represent the strength of the relationship between two individuals using the principal Graham mentioned: “weight is a numeric value quantifying the strength of a connection between two nodes” (Graham 206). Since there is no ‘undo’ button in Gephi, I continued to manipulate my data to see what else I could learn from it. I used numerous different filters and partitioned my results by degree, in-degree, and modularity.
The visualizations I created in Gephi gave me the ability to draw conclusions and see similarities/differences within the data set that I was unable to see in a typical spreadsheet format. Not only did I learn that where a node is in relation to other nodes mattered, but that the weight of the edge between them is also significant. I was able to see certain patterns that I may not have noticed prior that I can further dive into.
I feel that both Gephi and ArcGIS allowed me to narrow down and focus on just the Mary. These platforms gave me the ability to really illustrate the story of the Mary and learn about the numerous people, places, and purposes that went along with it. My findings helped me get a better understanding of the greater Trans-Atlantic Slave trade because I was able to draw connections and see relationships that I would not have previously picked up on.

Link to my WordPress Site: The Mary