
The first visualization I chose was “The Essence of Rabbit” compiled by the design firm Pictoplasma. It explores the art of around 600 artists on the topic of rabbits, their interpretations of the animal and showcases them in a what is effectively summed up as “a bunny mandala,” putting them in a color-coded formation that requires you to zoom in to view the art clearly. Looking back on my decision to view this following the three-stage model of perception in Meirelles’ book, I think that I was attracted to this during Stage 2: “Slow serial processing for extraction of patterns and structures.” It was the only one that had cartoons on it.
t is effectively summed up as “a bunny mandala,” putting them in a color-coded formation that requires you to zoom in to view the art clearly. Looking back on my decision to view this following the three-stage model of perception in Meirelles’ book, I think that I was attracted to this during Stage 2: “Slow serial processing for extraction of patterns and structures.” It was the only one that had cartoons on it.
This visualization showcases the differences in how a rabbit can appear in people’s heads and through the hands of artists, explored in different visual features. In essence, this also explores data feminism in the sense that this design firm is the one organizing the data and thus has a lot of power in choosing what designs fit into their aesthetic. The description of the project says that Pictoplasma asked the artists, however, there is not much more explanation to the process other than this. This opens up the question: “Was there anyone left behind?”

Although this visualization is all static data, the complexity of it that requires you to look only at one portion of the time creates a pseudo-dynamism, allowing you to choose what part of the mandala you want to see. However, the data is still static, and once you are done with the visualization, there is no way to compare parts of the dataset you want, an example of which could be only looking into the brown rabbits of the mandala. This visualization, while interesting, was no more than what they promised: “a bunny overdose.”

The second visualization I chose was “Visualizing Reddit Discussions.” It visualizes the comments and reactions of reddit threads from the front page, and is an interesting tool to see how discussions flow from topic to topic. The sizes of the bubbles note the engagement, while the colors other than black note the same author. This visualization is interesting as different conversations have different flows to them. Some stay anchored in the same main thread, whereas others start sub-discussions in a popular comment subthread.
This visualization is dynamic, changing from post to post and in real-time. The visualizations pull data from the main page, and it is possible to look into the threads you are interested in by pasting the link in the search bar. However, since the data is real-time, tracking it requires saving the post’s link to be able to see it later as it might not come up on its own again.
This tool, I think, serves to open up data interpretation a bit more. Complied over time, a single post’s growth could be an interesting thing to see, but in the current state of non-tracked change, this clearly dynamic visualization becomes static, in a way. These visualizations do create a new understanding of how people interact online, and having the choice of data set puts the power in the users’ hands. This does, however, bring up the question of pre-set algorithms as many of the users might not be familiar with coding, and the data that they end up with, therefore, might be biased after all.
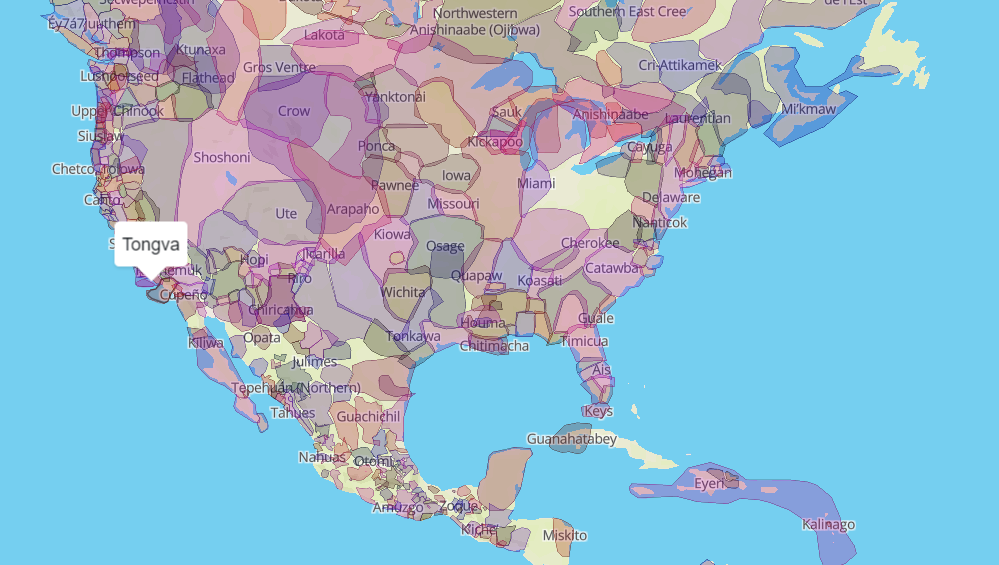
From the DH Sample book, I first chose Native Land, which visualizes the territories, languages, and treaties of native people. By looking at this data and being able to filter through the selected categories, you could find more data about a specific language or topic, and isolate it for better representation of your topic. It does allow for data to be viewed in different, but skewed perspectives, possibly, due to the data not being complete, Nonetheless, the project definitely provides ways to interact with the data and draw new conclusions.
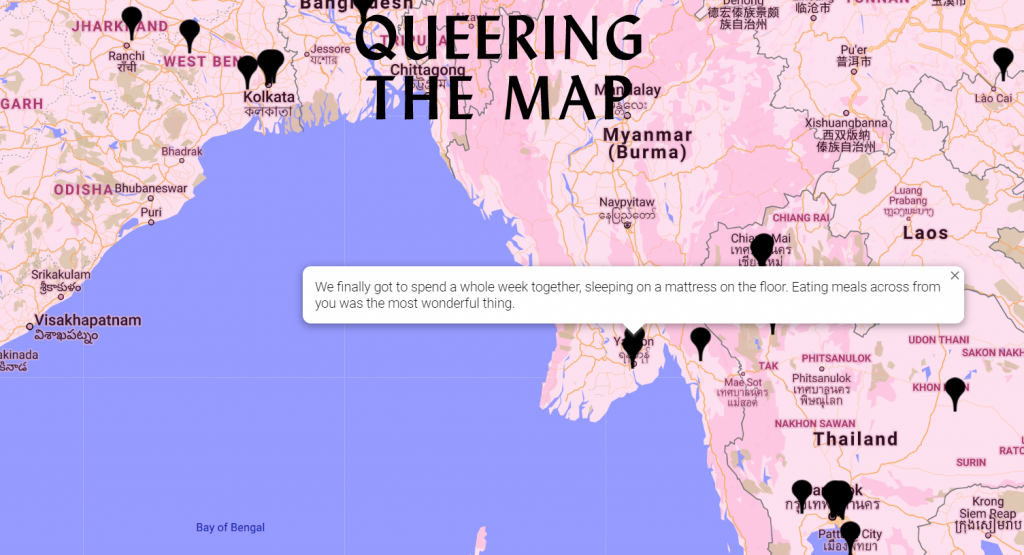
The second example I chose from the DH Book was “Queering the Map.” This allows people to share their own stories about queerness and contribute to a dataset the way that they see fit. It puts a lot of power into the hands of the visitor, which results in strange locations, but interesting stories nonetheless. This representation of data is simple, but the ease of being able to put your own narrative there and effectively changing the dataset might lead to new personal understandings about how and why people share their data.
