Visual Complexity
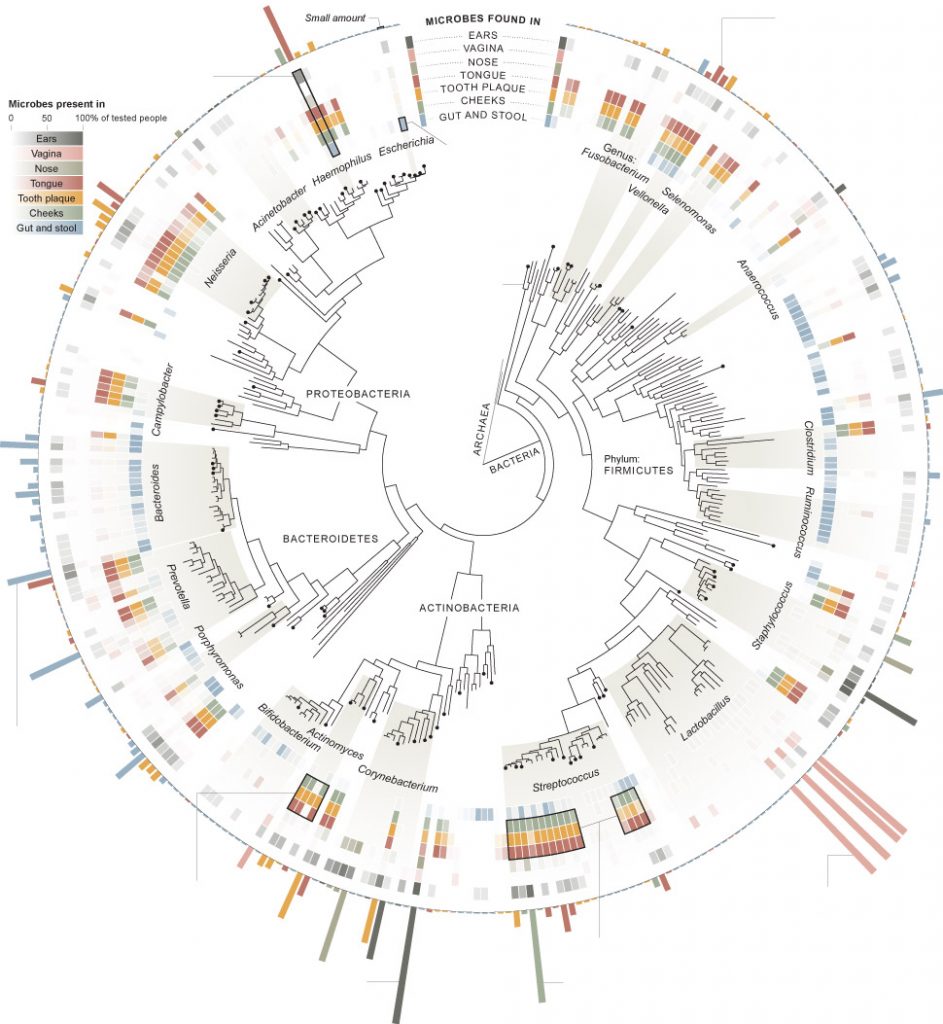
My first visualization, from the New York Times, analyzes the “invisible population” or the bacteria that live in different bodily sites on the 242 people tested. I chose this one initially because it visually appealed to me and I generally tend to like the graphics produced by the New York Times. In Design for Information, Meirelles discusses studies that show that different people are drawn to different “visual features.” I was drawn to the radial coloring and the inner ring resembling a gauge from afar. Though I may not have been initially interested in the precise breakdown of bacteria on a human body, the graphic caught my attention and caused me to take a closer look. Using compelling graphics to gather the attention of a reader is a technique that would be familiar to W.E.B DuBois, who “ produce[d] modern graphs, charts, maps, photographs, and other items that appeared to sparkle” in order to grab people’s attention because “an array of dry displays at the exhibit would have been ineffective in subverting the social Darwinist paradigm.”(DuBois 34) DuBois was trying to grab the attention of the masses (not just “a small circle of academics”) in order to “Chronicle the African American experience”(DuBois 34), while the New York Times is simply trying to get readers to turn to section D1 of the June 19th edition of the Times. Similar tactics, just different audiences.
Though represented radially, the hierarchical structure of the diagram resembles the “classification” type tree diagram as described by in Visual Complexity Mapping Patterns of Information: “Classification(a systematic taxonomy of values) …applies the hierarchical model to show our desire for order symmetry and regularity.”(Lima 25)
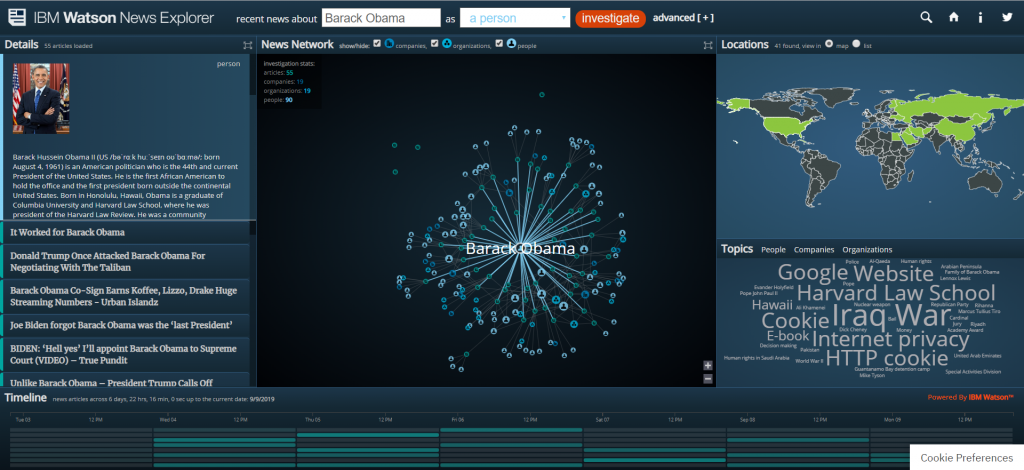
My second visualization is the IBM Watson News explorer which indexes thousands of news articles per day and analyzes them for content in order to link them together by topic, location, and people involved. This visualization appealed to me because of the location map on the right side. The news explorer uses color as a “preattentive feature” (Meirelles 22) to draw the eye to geographic locations where the searched item is tied to. You can search for a specific term or you can use the topic wordmap to find popular topics. When you select a topic, ( I have selected Obama in the above screenshot) it then uses the same wordmap to show you the most used words in articles about the topic (Obama here) as well as a map of the usage locations, and what Meirelles described in Design for Information as a node-link diagram(Meirelles 55) to detail the interconnections between your selected topic and another, as well as a list of the actual source articles where all of the information is pulled from.
The IBM visualization is clearly dynamic, as it pulls live data for recent news articles, while the New York Times article is static, it relies on the data taken from the study of 242 people, it never changes.
While analyzing these two visualizations, I thought about the influences of bias that are discussed in Data Feminism. Invisible Populations is based on scientific data, so the largest source of bias there would likely be in how the information is actually communicated to the reader. However, with the IBM visualization is a little less clear. Going to the information section of the website reveals that the system indexes 250K articles per day from 70K sources. While one might believe that this eliminates bias, I am not sure. The source articles are arranged in a manner that is less than transparent, with articles from sites like “spin.com” and “truepundit.com” showing up with the same frequency as more verified articles from sites like “nytimes.com” and “CNN”. Because of this scheme, extremely biased opinion pieces can show up in the results categorized as news. Because the system is automated, there is no moderation. Additionally, you can search for individuals, and it will show you articles and information linked to the person. However as Data Feminism implies, what’s important in this analysis isn’t who’s in the system, but “who” is missing. The system can only display information on people that the media is reporting on. If there are no articles about the person online, then to system, they effectively do not exist. You can only see the stories of the people who get in front of the news. As Data Feminism says, “Who any particular system is designed for, and who that system is designed by, are both issues that matter deeply. “(D’Ignazio and Klein)
This visualization, as compared to the last one, does allow the consumer to interact with the data in multiple ways. You can click on almost any of the visualizations to display more information or to use that as a search criterion for a new search. The New York Times visualization only provides a single means of interaction. However, considering the fact that one was designed for print media and the other was designed for the internet, this is not surprising, and also not a downside of the New York Times piece. I believe both visualizations allow for new understanding of the material. The IBM visualization allows you to see the connections between different articles and stories that are happening, that you would not have been able to easily detect before. The New York Times visualization provides less new understanding, but it does neatly sum up all of the information about the human biome.
DH Sample Book
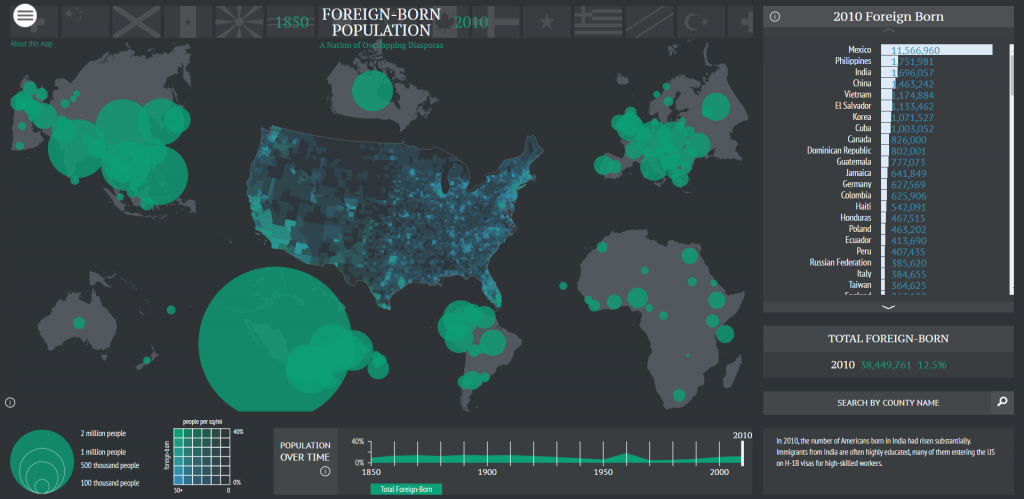
In the digital humanities sample book, I chose American Panorama, and the Six Degrees of Francis Bacon. American Panorama was compiled by the Digital Scholarship Lab at the University of Richmond. The project is a compilation of maps displaying information about the United States. The project is navigated by selecting a particular map and changing the parameters of it (each one is slightly different). The visualization allows the user to select from various criteria to change what the map displays. In the screenshot, I have the map of foreign born population. It allows the year to be adjusted at the bottom and then it shows where foreigners are from. You can even search by country on the right hand side. Information that this shows that a research paper would be unable to is the time element of the foreign population change. A paper would be able to discuss trends, and maybe even show a few years, but it would be unable to display the change over time in the same way that this can. The lab has a separate page that clearly lists the sources for the information. In terms of shortcomings, this project is pretty good. I think the main page could provide more information about the maps before you clicked on then, to give the reader more information about what they are about to open. The project was first created in 2015 (according to Wayback Machine) and has added maps since then. They currently have 8 maps.
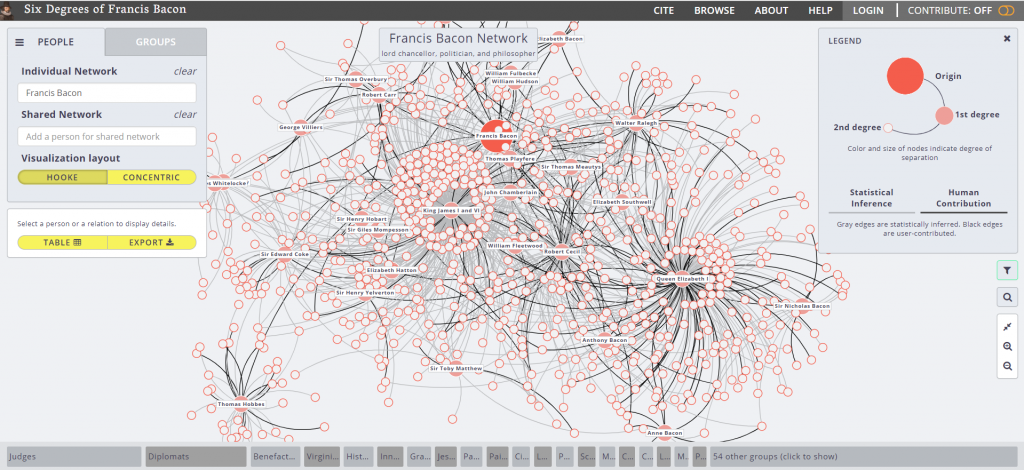
The second visualization is Six Degrees of Francis Bacon. The project is hosted by Carnegie Mellon University, with Christopher Warren as the project leader. The purpose is to recreate the “early modern social network”. The project is entirely open source, meaning that anyone can contribute to it. This is both good and bad. Like Wikipedia, this type of system means that data is generally correct and updated frequently, but it is often unverified. It is good for basic reference, but not for citing. This is also one of the shortcomings of the project, is the unverified nature of the data it uses. Over a traditional research paper, this project offers a dynamic dataset that is always expanding, and a level of broadness that can’t be discussed in a paper. One simply cannot communicate that volume of information in a traditional paper, however with this project it is easy due to the ability to navigate and view details on specific connections. I believe that this project does offer new ways of viewing this data. I had no idea the vast social network that existed in the days of Francis Bacon, and this project allows you to easily follow a trail of connections to new information. One other shortcoming of the project is the linking of people together. The legend indicates that a grey line means that the connection has been statistically inferred. This means that some of these could be incorrect due to shortcomings of the algorithm. Design-wise, I thought the project was very easy to navigate and was visually appealing, using different sized dots to indicate the degree of the connection, a technique discussed by Meirelles for pattern recognition.
