This project began with the name Quashie. More specifically it comes from a poem “Quashie’s Verse” I am examining in my master’s thesis. In this poem the poet/ sculptor Quashie negotiates how to create his poem in the shape of a clay jar, as opposed to a traditional verse form like a sonnet, for example. This poem is not only concerned with form but also with measurement. The shape of clay jar embodies the opposition between the linear European system of measure and a more dynamic, indeterminate approach to creating poetry. This idea recalls discussions of timelines and the transition to network theory. Isabel Meirelles succinctly describes the origins and orientation of the timeline: “The first graphical timelines that appeared in the mid-eighteenth century depicted time horizontally, with time moving from left to right … The orientation corresponds to the horizontal preference for depicting time, and the directionality of the authors’ European writing systems. Literature in perception and cognition has shown that we tend to use the direction of our writing systems to order events over time” (Meirelles 88). These are the very systems Quashie attempts to resist with his poetry.
I was happy to engage with network visualization, a form that resists arboreal structures, to understand more about Quashie’s origins. In Palladio I was able to create visualizations of the relations between Quashie and other iterations of the name through time using the African names database. The temporal boundaries were dates of embarkation and disembarkation. What was illuminating was the difference between the visuals depending on the organization of the data. The aesthetics of filtering by disembarkation signified a wholeness or unity among the names with one location and the center of the network. But placing the focus on embarkation created a visual that was truncated and broken, demonstrating the heterogeneity of the ‘origins’ of the names. Recognizing ways that networks could not only show relationships but also map geographies led to my continued exploration of Miller’s poetry in Gephi.
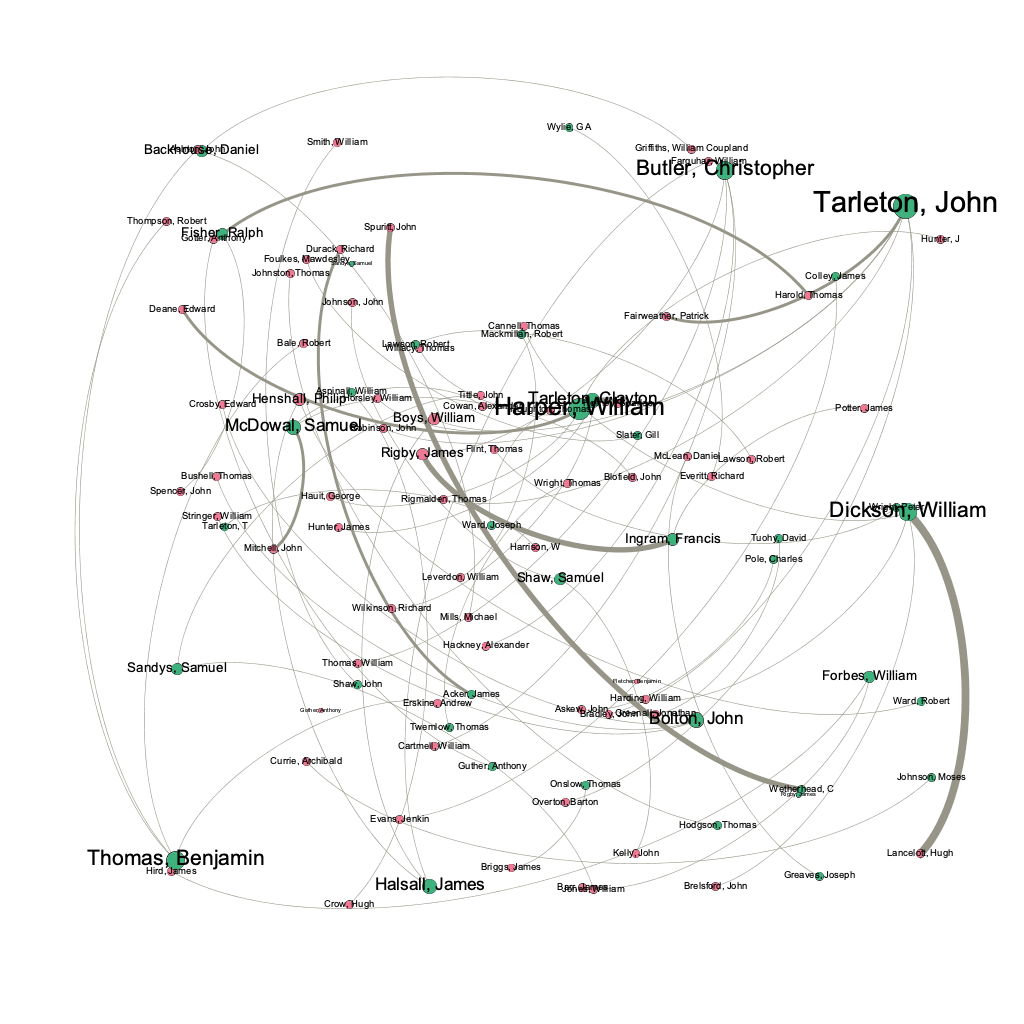
How does Kei Miller produce invisible maps through his poetry? This question is motivated by Manuel Lima’s statement that “network visualization is also the cartography of the indiscernible, depicting intangible structures that are invisible and undetected by the human eye” (Lima 80). In Gephi I explored how words that signify systems of measure are used beyond “Quashie’s Verse,” mapping the relations between words like “measure” and “distance” in his collection, The Cartographer Tries to Map a Way to Zion. My investigation of the cartography of networks, has been largely motivated by the cartographic concerns of Miller’s poetry collection generally and “Quashie’s Verse” specifically. For this reason, I paid attention to the shapes produced by the community of words among the poems. I borrow from Johanna Drucker’s assertion that “graphic expression is always a translation and remediation” (242). For and I am concerned with demonstrating how data may be understood as an art object and ways that the re-spatialization of the text carries meaning differently from its original form. I was fascinated by the shape produced by the Force Atlas layout, for in the top right corner of the visualization emerges a spider. The spider points toward Anancy, who is constantly metamorphosing from man into spider and back, and he appears several poems across the collection. The Anancy figure is significant, for he is a trickster who plays with and plays on language, and on an epistemological level invokes an endless play of signifiers. Then, seeing a version of Anancy appear in this new map prompted me to think more about how maps can be visible or invisible, and ways that lines, measurements and algorithms may be humanistic.
My project, then, picks up where I left off with Gephi. While I am interested in this unfamiliar or distant way of approaching my reading of Miller’s collection, I find it valuable to create a more nuanced picture or map of relations using tools that allow me to engage with the poetry in their original form. First, I turned to Poemage, a visualization tool for exploring the “sonic topology” of a poem. I am interested in visualizing the relationships between sounds in the poems that include Quashie. While Gephi allowed me to draw or create a map of relationships between specific words in the collection, Poemage allows me to create a map between specific sounds in individual poems. Using these tools, I analyze the shapes that emerge from mapping the relationship between words and sounds in the collection and within the poems. To accomplish this, I do a combination of close reading and distant reading to produce what Tanya Clement calls a differential reading. She notes that this method “defamiliarize[s] texts, making them unrecognizable in a way (putting them at a distance) that helps scholars identify features they might not otherwise have seen, make hypotheses, generate research questions, and figure out prevalent patterns and how to read them” (2). In addition to Poemage I use Voyant to get a view that combines the closeness with the text that Poemage fosters and the distance from the text that Gephi offers, allowing me to engage with The Cartographer Tries to Map a Way to Zion in both familiar and unfamiliar ways.
I also wanted to continue exploring network visualization and analysis in Miller’s collection with Gephi. With that I turn to the field of geocriticism, where “To draw a map is to tell a story in many ways and vice versa” (Tally 4). The narrative between the cartographer and the rastaman not only tells a story, it also draws a map. Since the writing of the poems function to create maps I decided to extend the community of words I map to words related to poetry and verse. To do this I appended my initial nodes and edges table to include words like “shape”, “draw”, and “lines,” along with the poems they appear in. To create a more fulsome picture of the mapping relationships, I also decided to include all the iterations of the word “map” in my dataset.
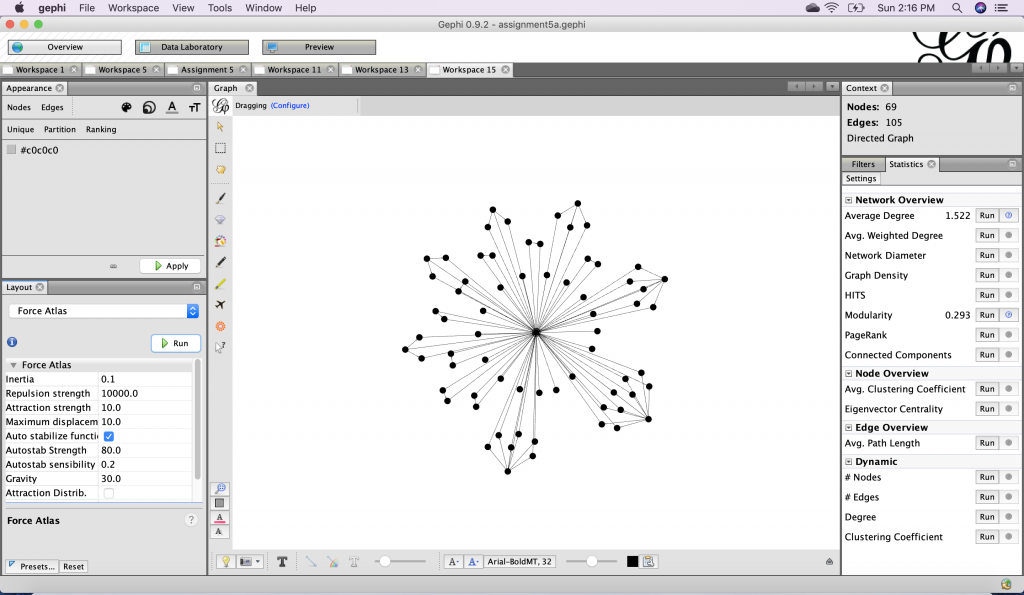
In Gephi the image produced using Force Atlas has a striking resemblance to a compass. I noticed this because there is a compass on the cover of The Cartographer Tries to Map a Way to Zion.


An important distinction between the two is that in my design the rastaman at the center. This displaces the cartographer as the symbolic figure of mapping and map design. The visualization I created also demonstrates the play between each of the character’s operations. Insightfully, in “xx” the cartographer states that “every language, even yours, / is a partial map of this world” (2-3). Comparing the first network to the second one I produced in Gephi, it becomes clear that the first – with fewer nodes and edges – is indeed a partial map of the collection. But the same could be said of the second one, as the biases of my own research (specific words) implicate the resulting image. No one view or perspective is definitive. This motivated me to see what may be revealed if I changed the layout.


I created the second visualization using the Fruchterman Reingold layout to demonstrate the diverse relationship between the different words in The Cartographer Tries to Map a Way to Zion. Each word is customized to have a distinct color. I used the custom palette to color the nodes with browns and neutral tones in an attempt to mimic the cover image. But I ultimately decided to switch the palette to a variety of bright colors in order to illustrate the variety of words that make up this map as opposed to uniform colors that risk implying there is uniformity in navigating through a space or place.

I understand the following visualization to operate as a compass, not necessarily to orient the viewer within the collection but to point toward its complexities in a nonlinear way.

Though seeing the relationship between the variety of words in a network diagram is illuminating, I had the desire to map some of these words in their individual contexts. When I first tried using Poemage I was interested to use the tool to investigate “Quashie’s Verse” especially because of the distinct shape it has. However, after fiddling with the poem in a plain text file I discovered that the formatting in the program did not substantially change.


Instead I focused on a poem that also included Quashie, crafting poetry and rhythm. Miller’s “xvii” replicates a dub poem, which is a form of performance poetry that incorporates a beat, usually from a drum – this made it a good candidate for Poemage. After uploading the poem to the program, I decided to focus on assonance. Doing this sort of distant reading allowed me to see a sonic pattern; I noticed the lines that connected words with an “ae” sound.

This prompted me to think more about the relationship between “rastaman”, “iambic” and “Quashie.” When considering Quashie’s project of writing with a verse form intuitive to him instead of the way he has been “instructed / now in universal forms” generates similarities between his task and that of the rastaman (17-18). Both of these men resist what the iambic metre represents. Playing on the meaning of metre as a unit of measure to create maps and a measure with which one crafts poetry is not only a way to showcase the rigidity traditionally associated with these endeavors, it also links these elements in a way that resists it. The use of assonance is then a way that Miller creates an invisible map, for he also takes space into consideration (even outside of his concrete poem). With Poemage I noticed the even line spacing between those instances of “rastaman”, “iambic” and “Quashie.” Each of the words frame the repeated “DUP-dudududu-DUP-DUP” sound, which speaks to the departure from the iambic metre with one that is intuitive to the speaker/rastaman. Moreover, this highlights the relationship between the rastaman and Anansi in illustrating a “partial map” of Jamaica, one that is not seen by the cartographer, and figures that represent this mathematical, objective and even colonial perspective.
This examination was so fruitful in augmenting the work I began with Gephi that I was excited to use Voyant. The corpus consists of each of the thirteen poems that contain a version of the word “map.” After transcribing a few of the poems to experiment with in poemage I continued to put each of the poems in their own plain text files to upload them to Voyant Tools. I had the idea to visualize the “map” in Voyant spatially. This idea came from my experience negotiating whether to distinguish “map” from “mapped” and “mapping” in the nodes table for Gephi and their frequencies within a single poem. Using a text analysis tool lends itself to working with the text in its ‘whole’ form and observing trends within the entire corpus. In this way Voyant kind of combines my desire to think about the collection as well as the individual poems by examining how a group of these poems relate to each other.

The Trends graph allowed me to see the most frequent words in the corpus, two of which included “map” and “maps.” I also used the cirrus tool to visualize the relative frequencies of words in the shortest poem. Despite its short length, it contains one of the most significant lines in the collection and to my argument: “I will draw a map of what you never see” (19). It is ironic that some of the smallest words are “bigger” and “larger” while one of the bigger ones is “guess.” I believe this speaks to the pivotal place of indeterminacy in the way the rastaman (and Quashie) understands mapping. It also calls an important connection into sharper focus; the shortest poem is the one that contains the largest number of the word “map.”


Thinking about this interesting occurrence, prompted me to consider using a tool within Voyant to visually contextualize the appearance of “map” and “maps.”

Like the Gephi Force Atlas layout, if one looks closely this Word Tree visualization also resembles a spider. The repetition of the spider speaks to the network that a spider like Anancy would produce by spinning his web. This web is a complex one, made up of words, and like many spider webs remain nearly invisible to the human eye. Flexing my design skills in Gephi and making use of the built-in algorithms in Poemage and Voyant I am able to show several versions of the (in)visible maps that Kei Miller creates through his poetry.
Works Cited
Clement, Tanya. and Price, Kenneth M. “Text Analysis, Data Mining, and Visualizations in Literary Scholarship.” Text Analysis, Data Mining, and Visualizations in Literary Scholarship, 2013.
Drucker, Johanna. “Graphical Approaches to the Digital Humanities.” Schreibman, Susan, et al. A New Companion to Digital Humanities. Chichester, West Sussex, UK, 2016.
Lima, Manuel. Visual Complexity: Mapping Patterns of Information. Princeton Architectural Press, 2011.
Meirelles, Isabel. Design for Information : An Introduction to the Histories, Theories, and Best Practices Behind Effective Information Visualizations. Rockport, 2013.
Miller, Kei. The Cartographer Tries to Map a Way to Zion. Carcanet, 2014.
Tally, Robert T. Topophrenia: Place, Narrative and the Spatial Imagination. Indiana UP, 2019.