Kat Culliton
a)
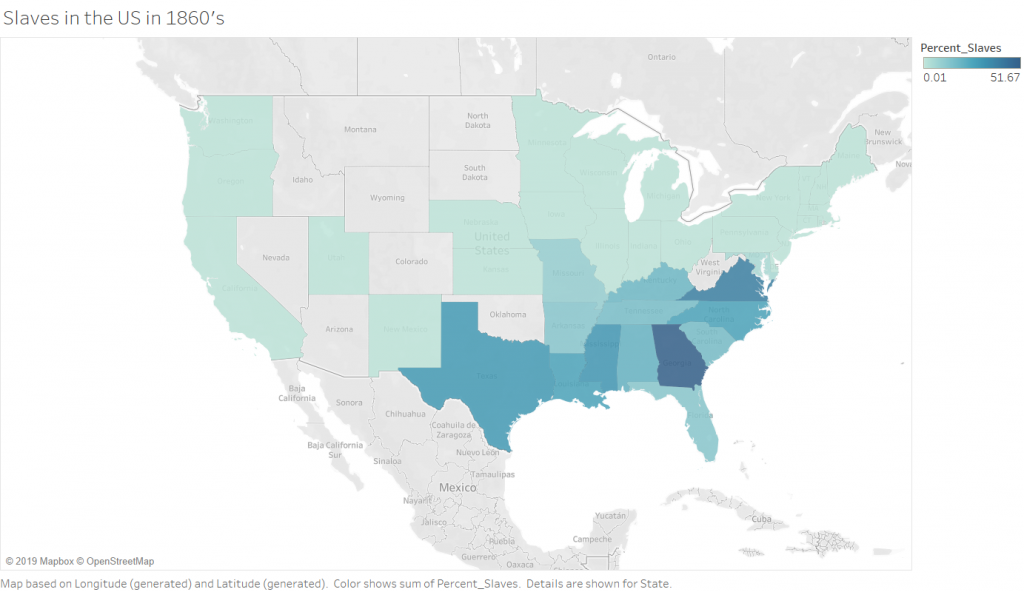
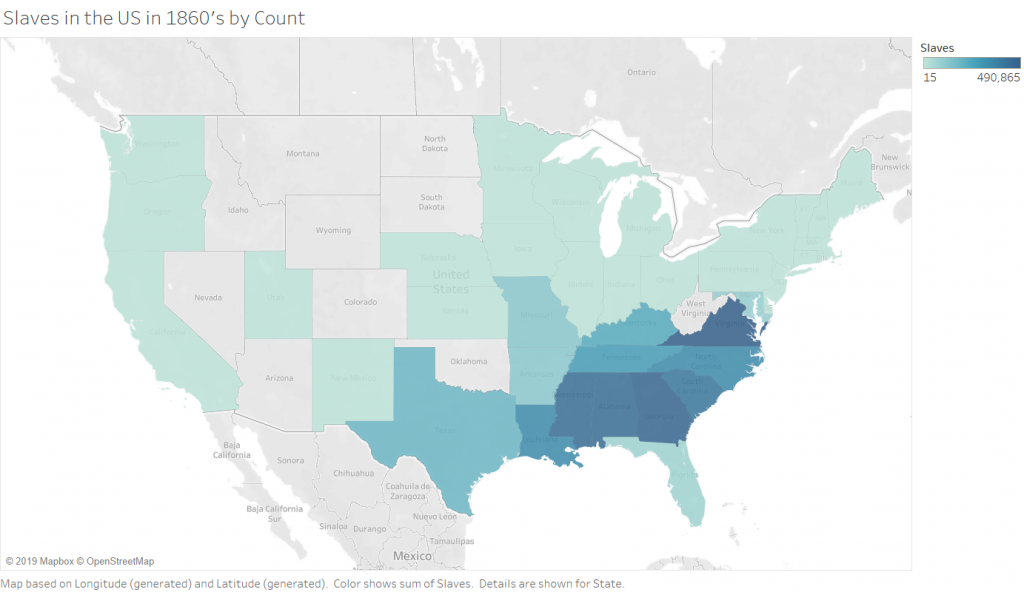
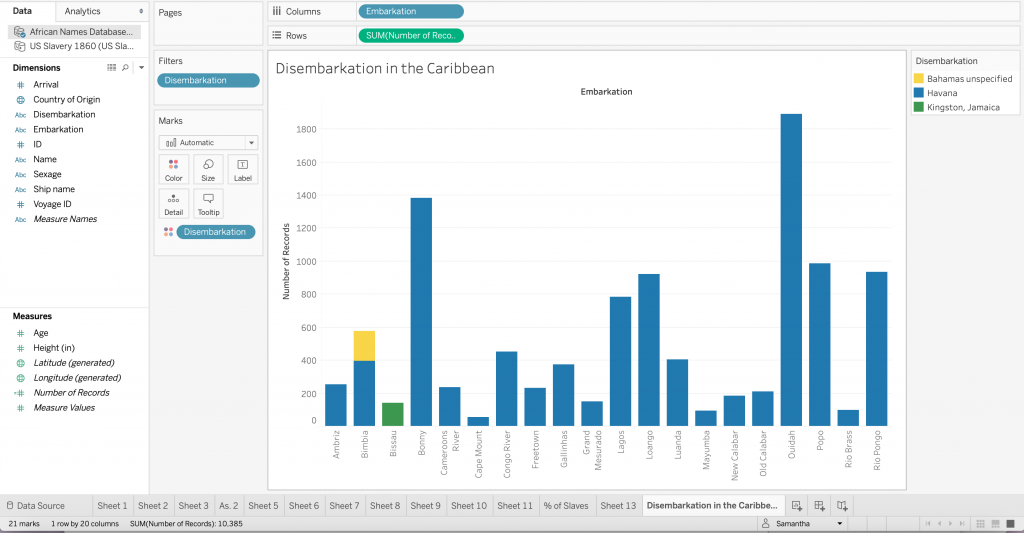
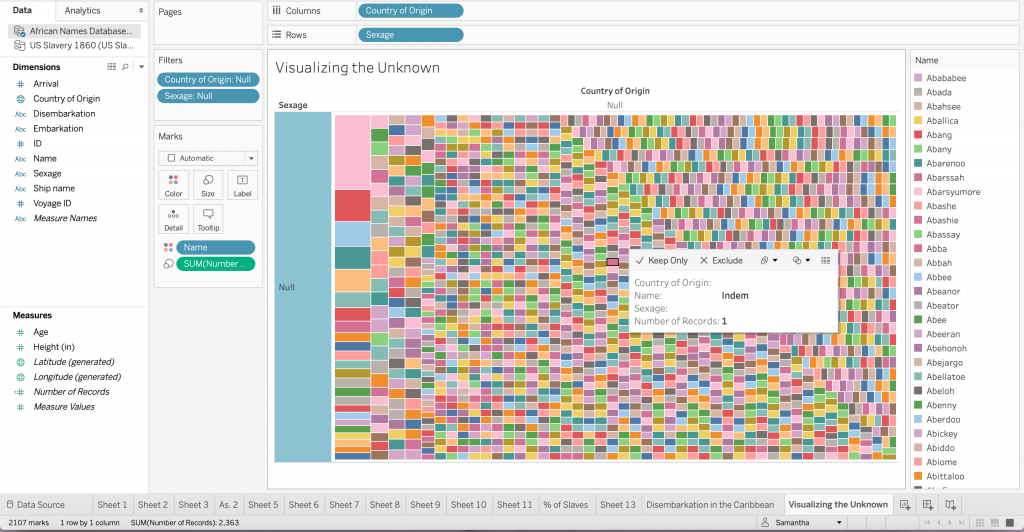
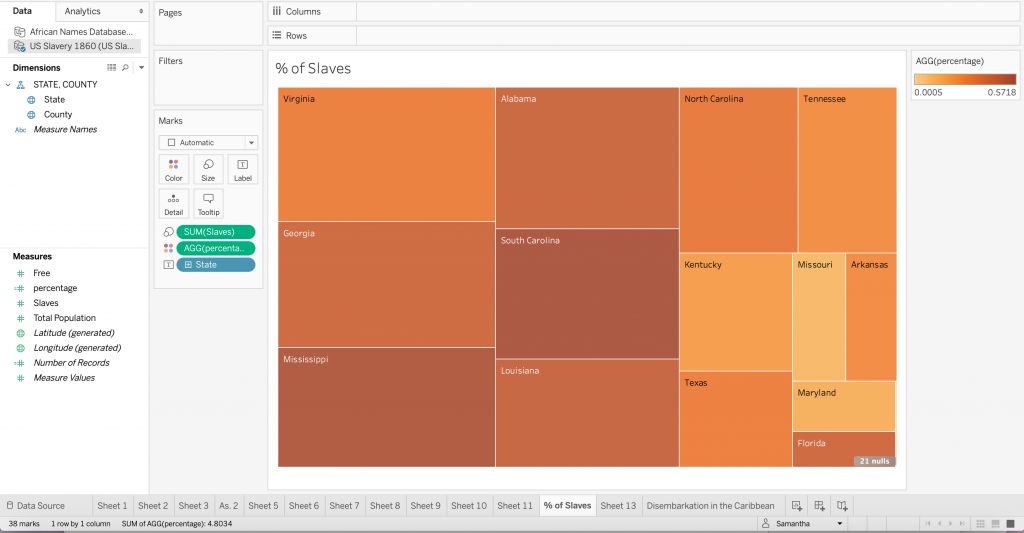
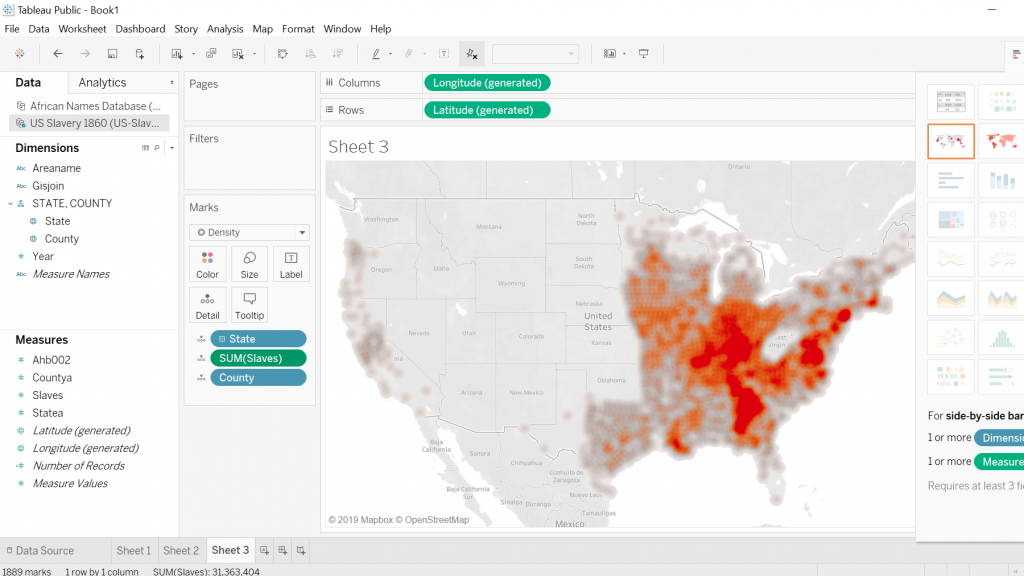
It was extremely helpful having Ken come in to walk us through Tableau. He was an expert at data manipulation and visualization. It made me a lot more curious about the platform and all it could do as I followed along with him as he made intricate, yet visually appealing graphs. While I still have a long way to go with learning Tableau, I enjoyed playing around with the colors, filters and different graph styles to create an image that revealed a compelling story. I think the data we were using, specifically in this case study, needed to be shown in a way that did justice to the hard facts revealed in it. The Excel template was a poor way to translate such important, and chilling, data to the eye. It needed to be constructed in a way that told the story through visuals, and not through numbers.
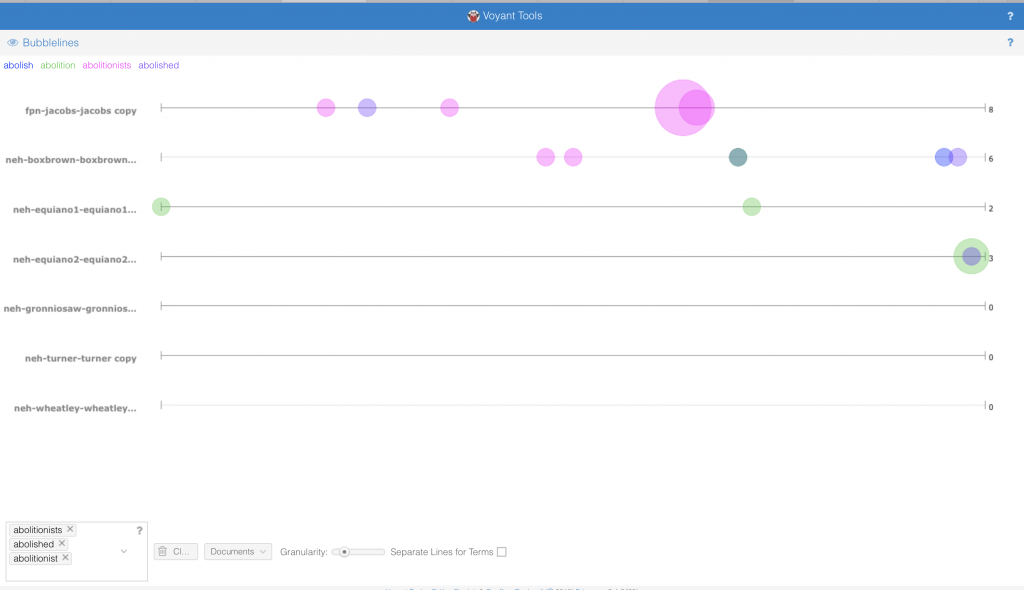
The data we constructed in Voyant also dealt with slave narratives. As opposed to the Excel sheets we were looking at, the writings of these narratives told a story that definitely did justice to what was occurring during that time. However, by constructing the textual data under a different lens, a new perspective was brought to the texts. We were able to compare and contrast 7 different narratives and uncover a different interpretation of the text.
b.
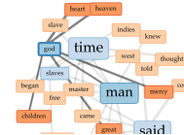
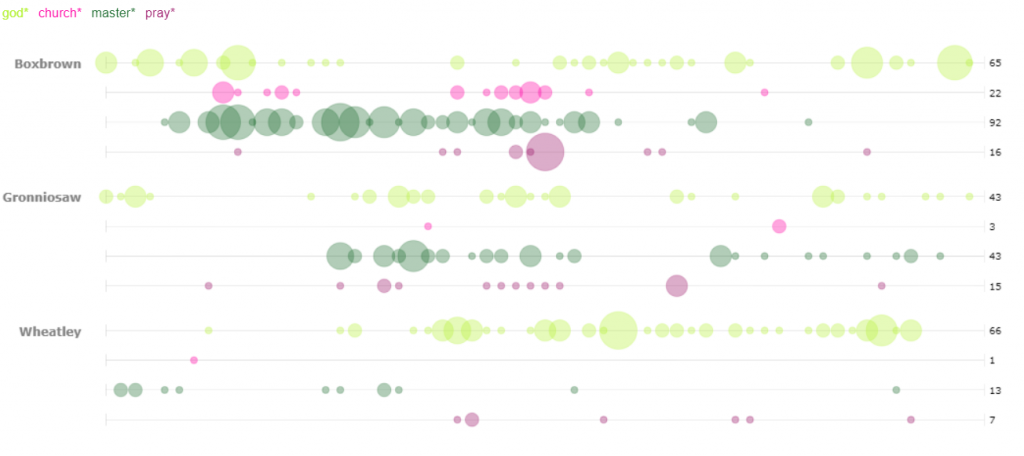
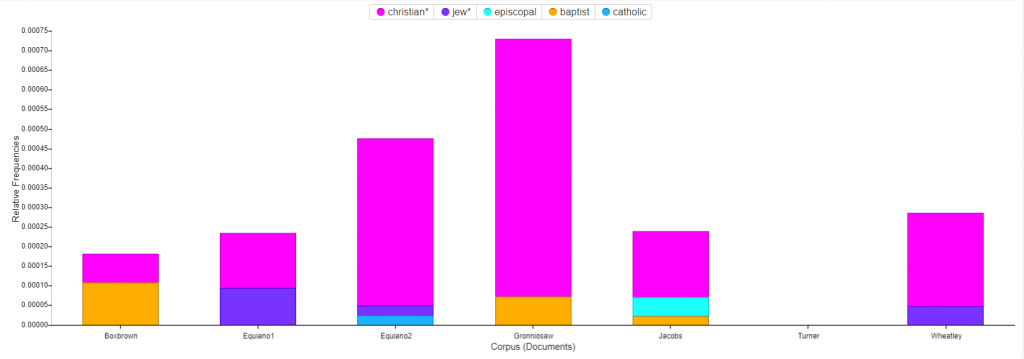
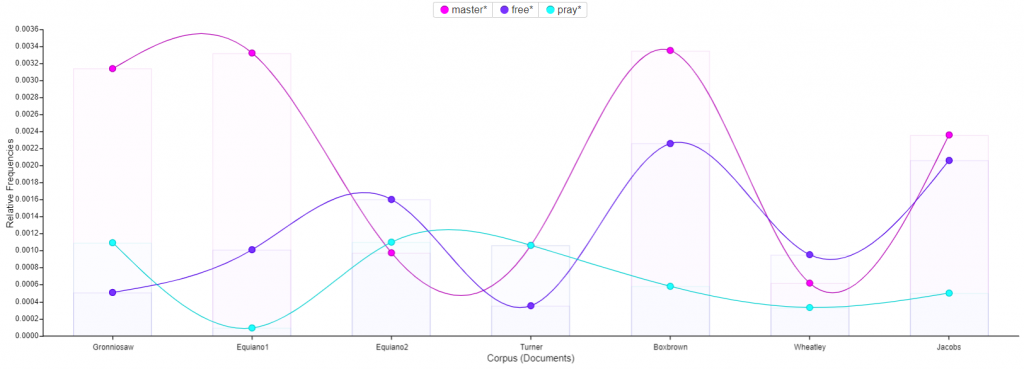
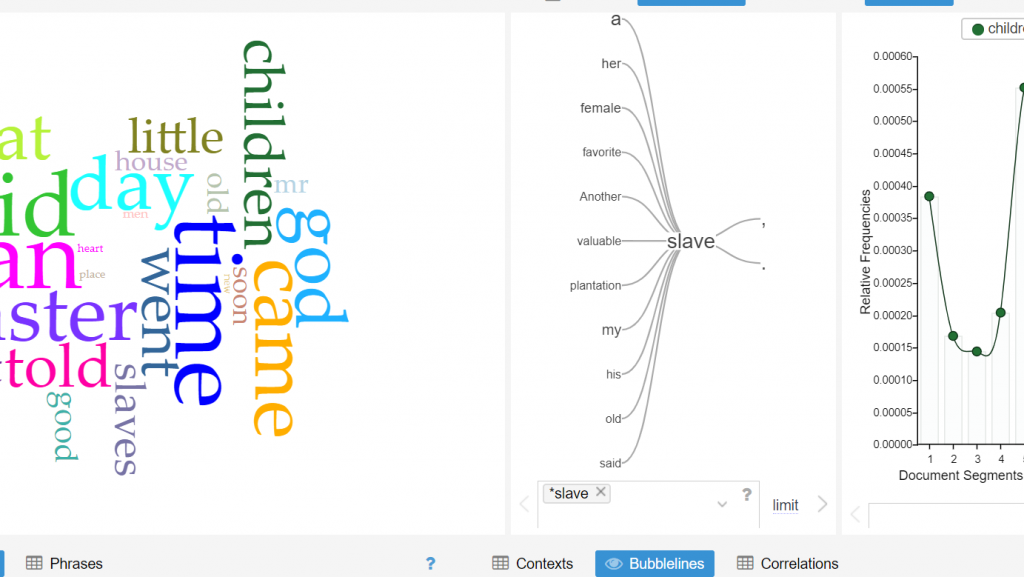
The role of religion in the text transcripts is interesting to me. In the first corpus, I highlighted the word “god”, to see what other words correlated to it. I was expecting to see words like heart, heaven, mercy and even great. I was surprised to see words like man and children tied to it. I would infer that the relation between children and God, is all of their prayers to God to watch over their children. Man is a more interesting correlation. When I clicked on the word “Man” it was connected to “Slave” and other words such as, “Master”. The other terms were not necessarily biblical, but rather darker, slave-like terminology.
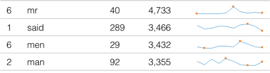
The second visualization shows the most frequent words transcribed in the text. I think it is important to note that “Mr.”, “Men”, and “Man” are within the top 4 words. During this period of time, we see that society was clearly dominated by males. My follow up question would be are the texts we read today still predominantly masculine? Is there a way to follow the women’s movement throughout text corpuses to compare the frequency of masculine and feminine words throughout time? Although I am a numbers person, literature sometimes shows and speaks more than hard data.
c.
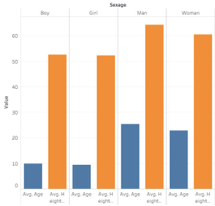
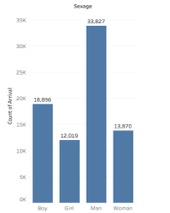
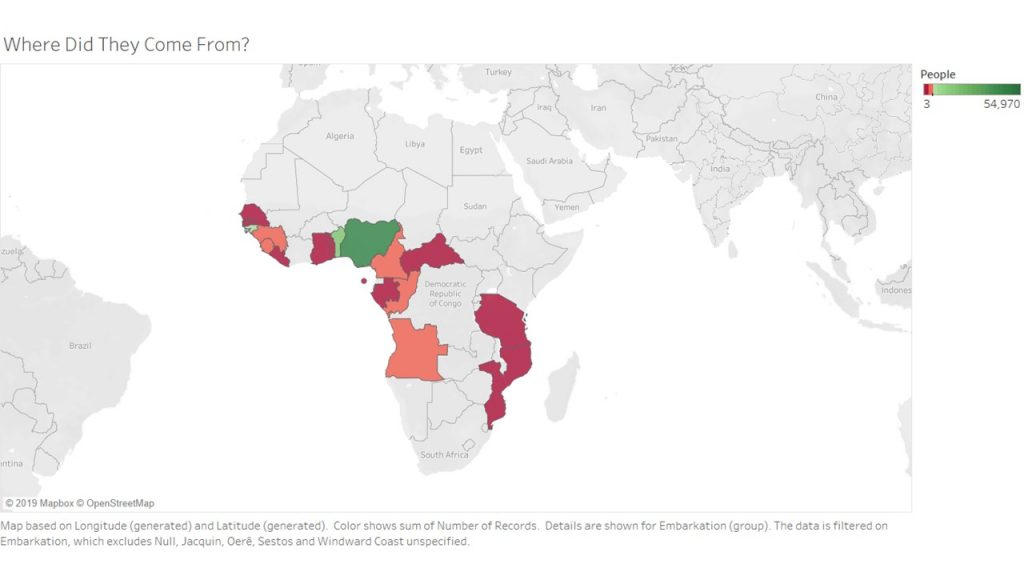
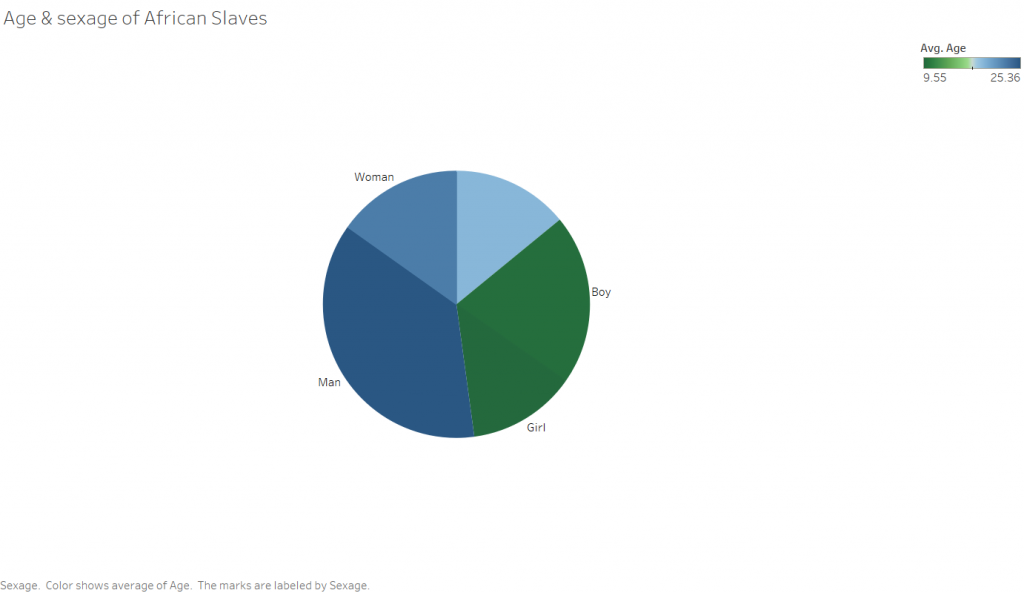
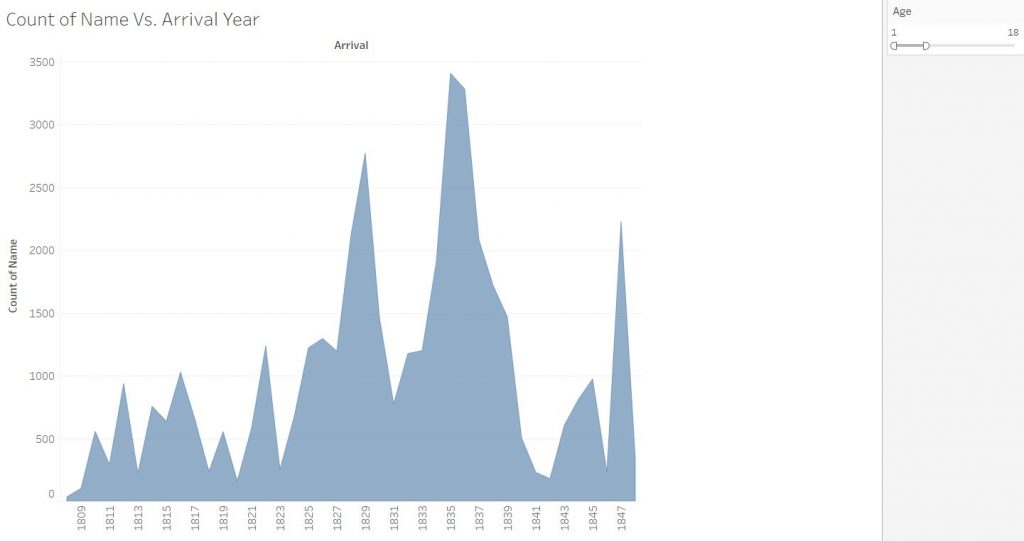
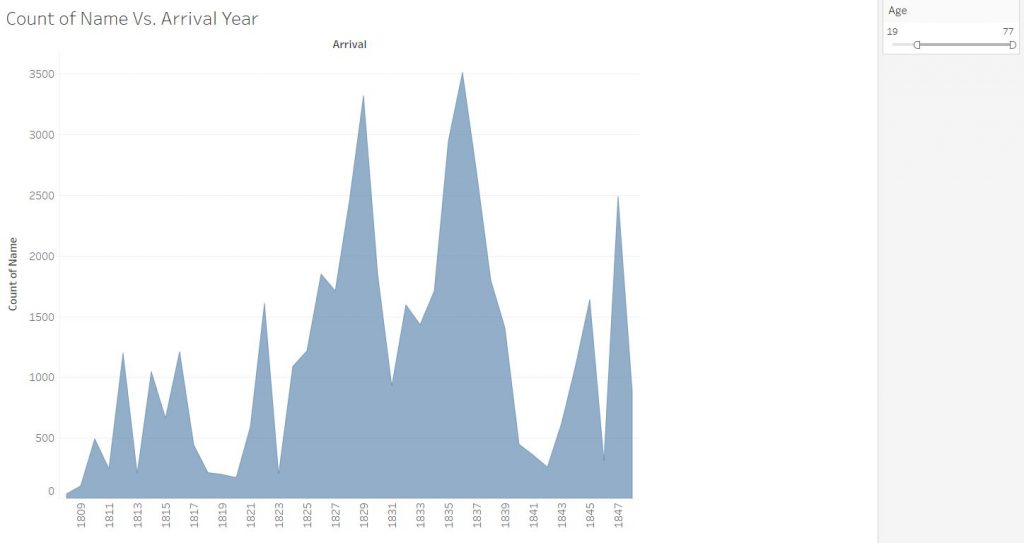
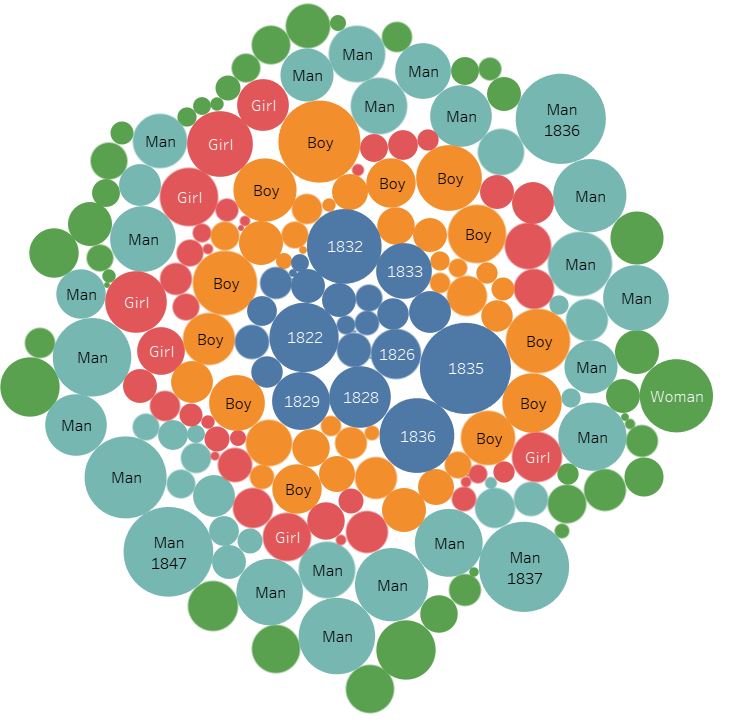
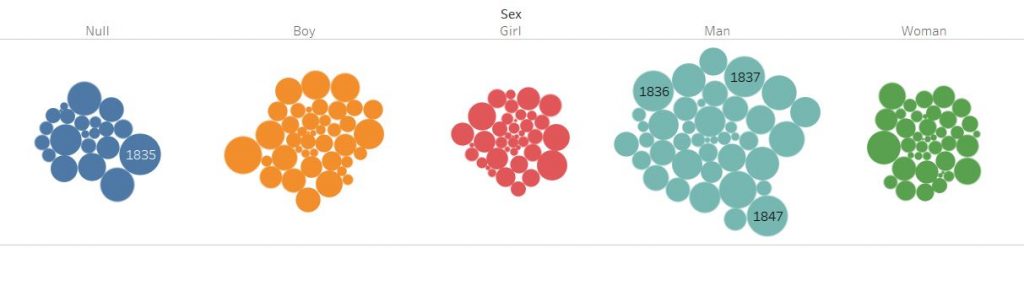
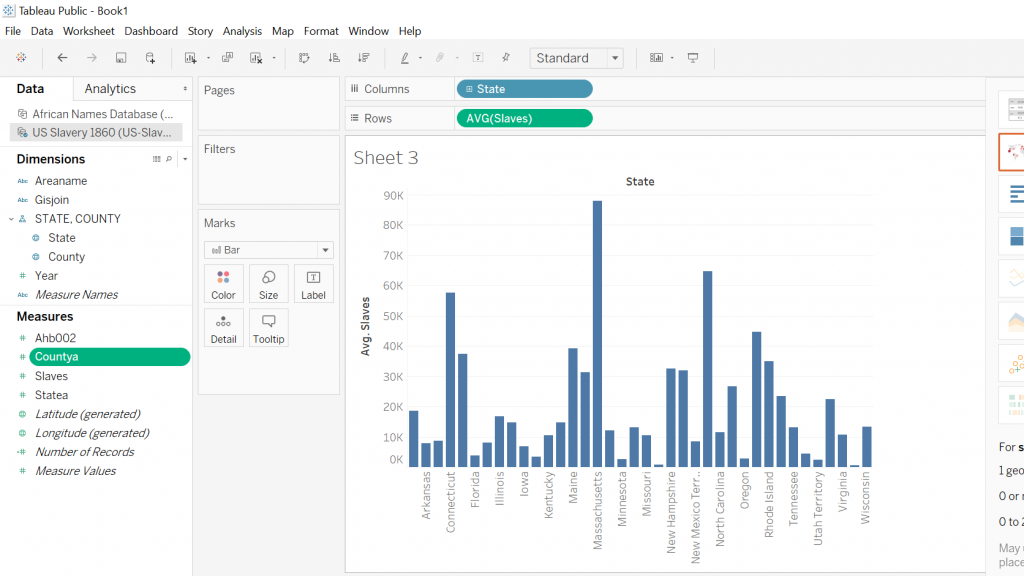
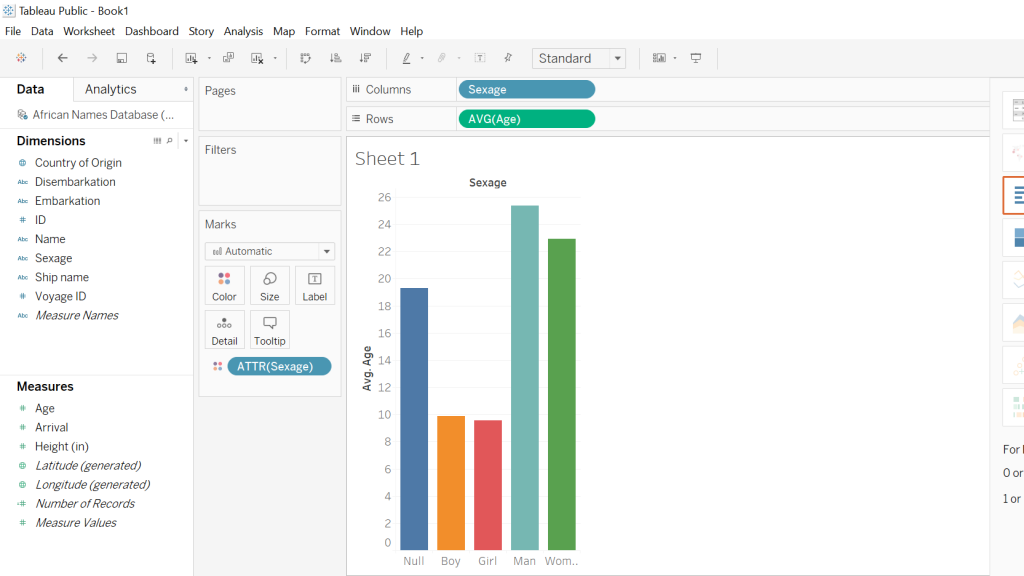
I was interested in building these visualizations – while they might be simple to the eye – I feel as though they tell an important story. I was first interested in analyzing sex. I am currently taking my Econ Senior Seminar, The History of the United States Economy. We dive deep into what composed of the economic sector major throughout time. We look at slavery closely, and analyze how it impacted the economic growth of the nation. It is hard to take an economic lens while analyzing such a fragile topic, but we often talk about the differences in male and female contributions to society. Men did a lot more of the physical labor such as working in the fields and constructing navigation and transportation routes, but women were extremely necessary in the house. While their labor wasn’t as physical, they contributed a lot – yet why were there so few women? I wanted to see the actual difference between men and women slaves in the United States. We see from the graphs that more men and boys are transported than women and female.
I then wanted to know whether men and boys were physically more equipped and had a greater standard of living than women or not. I added in height as a proxy for health. It is interesting to me that men and women are almost the same height, as well as boys and girls. Further analysis must be done to confidently say that they were equally as healthy, yet men contributed more economically. In reality though, from what I am learning in Econ, that might not necessarily be the truth. I would like to extend this graph further and add an economic component to it.
d.
It is important to note that the two platforms we are using to analyze and visualize data are unique in the type of data they can construct. Voyant interprets qualitative data, while Tableau interprets quantitative data. As a quantitative person, the Tableau platform came naturally to me in terms of being able to navigate the software. I spent the summer as a financial analyst and sales rep at Bloomberg and am familiar with constructing numbers in a way that is visually appealing to the eye. Although I had never used Tableau, I was immediately intrigued by how clean, yet detailed it was for being a free software. I’ve used Adobe Analytics, ComScore, Excel, and the Bloomberg Terminal to analyze data, and now Tableau. I will say that Tableau had the most user friendly and visually appealing graphics. It is also a “one stop shop” platform.
I, personally, was more overwhelmed by Voyant. I feel like there is a lot more moving components to it and didn’t necessarily understand the differences between the titles of each visualization. It was easy to play around with, but definitely took some exploration. I was intrigued by it because I don’t spend a lot of time on text analysis tools. I will credit Voyant in saying that the visualizations they gave told a story and allowed me to draw parallels between the texts that I wouldn’t have seen while reading and annotating text by text. I think this would be a useful tool, along with Tableau, to bring back to Bloomberg post-graduation. A lot of trends throughout the news articles (which we are constantly looking at) can be seen clearly and in a user friendly way.
e.
I think it the creation of visualizations and corpuses is verified by Tanya Clement’s statement. It is important to recognize that we are condensing and analyzing a text in a virtual way that is not as authentic as the original text itself – yet by viewing it using the tools of corpus construction, we bring light to many trends, sequences, patterns, and correlations we might have missed otherwise. I believe This encompassing vantage points does bring justice in that an algorithm was able to translate the text into a way that can be analyzed qualitatively, but that the text itself is more authentic.